一些思考
很多人可能认为算法和数据结构没有多大用处,恰恰相反,我们使用的一些编程语言核心类库和一些api底层就是对数据结构加算法而组成的。很多人可能最多就是看看源代码,写点分析源代码文章,那都是已经现有的东西照着思路读就行了,而算法完全是不一样的,一个算法题解题思路可以是多种,多种数据结构解决,那这么多解决问题方法,差异在哪啦呢?这就得看自己本身对各种数据结构的特性的了解程度了,算法是应用于数据结构之上的东西,如果没有掌握好数据结构,怎么谈应用去解决实际问题呢?
我看过很多人,或者大多数开发者最多就是一个API操作员,搞点框架拼积木一样,能跑就行了,当然框架能解决问题也是,也能减少开发复杂性,重复工作,那都是一些固定死的业务逻辑罢了,真正的问题是针对你业务问题而且填写你业务逻辑问题解决问题,框架做的最多就是把你外围的工作或者基础配置搭建好而已。真正的业务逻辑还是根据个人的需求去完成,框架也是别人包装出来的,但是它包装不了不同问题的解决方法,只能起到一些刚开始的约束作用,最后你会发现随着需求的改变和业务问题,你的代码还是要解决问题,还是自己去写核心逻辑代码,所以不要小看数据结构和算法的重要性。当然很多人选择if else一把梭然后call api完成任务罢了,我觉得一个好工程师最少要掌握设计模式编程范式,数据结构的应用去解决问题,那样代码水平才能提高。
我看到很多人在一些语言上写溜的不行,换到Rust上就寸步难行。。实际上根本什么都不懂,面试靠着是八股文,八股文这个东西我觉得只要你不笨有脑子是个人都能背,所以我现在看到那种八股文广告就烦的狠,不是背还是要理解,这样才能技术有提升。
而真正一名工程师应该是从上到下知识系统和认知面要很广,操作系统,计算机组成,计算机网络,编译原理,数据结构加算法,这些才是组成今天的计算机的东西,不说废话了本文将介绍堆的实现和堆在实际问题上的应用。
堆结构
什么是堆?堆是从完全二叉树演进过来的,至于什么是完成二叉树我这里就不介绍了。堆有两种组织形态:根节点的值小于左右孩子节点的值称为小顶堆,根节点的值大于左右孩子节点的值称为大顶堆。
堆的用处用很多,例如解决动态数据添加删除问题,从小到大排序,可以在O(1)的时间复杂度里面获取最大值或者最小值,0(logn)的时间内添加一个节点或者删除一个节点。获取一组序列的最大的K个元素,时间复杂度为NlogK,求一些排名前几的这些问题也可以使用。优先队列就是一个例子,如果一个节点频繁添加或者删除可以把他放入大顶堆堆顶上,还有数据是动态的每次要根据新进来的数据做出调整这种也适合使用堆。
最典型的应用就是高效的定时器任务扫描了,这个在Go语言里面的定时器底层有用到,具体过程如下:
假设我们要设计一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间比如 1 秒,就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。像这样每次扫描的时候,把所有任务都扫描一遍,肯定很低效,如果任务比较少还好,任务比较多的话,就比较耗时。那有更高效的办法呢?答案是有的:我们可以把每个任务都存储在优先级队列中(以触发时间为优先级的小顶堆),这样最先执行的任务就在堆顶,每次扫描的时候只需取出堆顶任务,拿对其他任务的定时时间和当前时间比较。
堆构造
上面说了这么多,那如何构造一个堆呢?例如下图右边就是一个大顶堆:
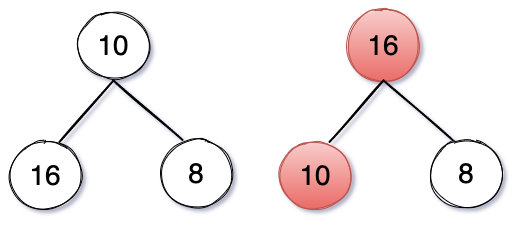
构建很简单就是组成堆的3个元素分别比较交换位置,把最大的放到堆顶上,如果有子节点的话还要继续调整子节点,下面是我Java实现的代码:
public static void heapify(int[] tree,int len,int i) {
if (i >= len) {
return;
}
int max = i,left = i * 2 + 1,right = i * 2 + 2;
if (tree[left] > tree[max]) {
max = left;
}
if (tree[right] > tree[max]) {
max = right;
}
if (max != i) {
int temp = arr[i];
arr[i] = arr[max];
arr[max] = arr[i];
heapify(tree,len,max);
}
}
如果输入的数组顺序是无序的,次数我们还需要对数组进行调整,以满足大顶堆的要求,原理就是对最后一组的3个元素依次往上调整直到到堆顶即可完成堆的构建,下面是我的Java代码:
public static void build(int []tree,int len) {
for (int i = (len - 1) / 2; i >= O; --i) {
heapify(tree,len,i);
}
}上面build函数就可以对一个无序的数组构建成一个大顶堆结构了,实现了大顶堆就可以实现堆排序,堆排序过程也是相对很简单的,过程就是把堆顶的元素换到叶子节点的位置,把叶子节点调整到堆顶,但是如果是不能满足堆要求还要进行调整,然后重复这个过程整个数组就是有序的了,下面是我的Java代码实现:
public static void sort(int[] tree,int len) {
build(tree,len);
for (int i = len - 1; i >= 0; i--){
int tmep = tree[i];
tree[i] = tree[0];
tree[0] = tree[i];
heapify(tree,i,0);
}
}然后就可以进行排序了,排序代码如下:
public static void main(String[] args) {
int[] arr = { 2, 5, 3, 1, 10, 4 };
Sort(arr, arr.length);
System.out.println(Arrays.toString(arr));
// [1, 2, 3, 4, 5, 10]
}下面这个版本是使用Go实现的,如果想使用跟多数据结构可以安装这个包,这个模块也是本人我编写的,支持泛型类型,Github地址:https://github.com/auula/coffee
package heap
func Sort[T any](tree []T, fn func(x, y T) bool) {
Build(tree, fn, len(tree))
for i := len(tree) - 1; i >= 0; i-- {
tree[0], tree[i] = tree[i], tree[0]
Heapify(tree, fn, i, 0)
}
}
func Build[T any](tree []T, fn func(x, y T) bool, len int) {
parent := (len - 1) / 2
for parent >= 0 {
Heapify(tree, fn, len, parent)
parent -= 1
}
}
func Heapify[T any](tree []T, fn func(x, y T) bool, len, i int) {
if i >= len {
return
}
var (
max = i
left, right = i*2 + 1, i*2 + 2
)
if left < len && fn(tree[left], tree[max]) {
max = left
}
if right < len && fn(tree[right], tree[max]) {
max = right
}
if max != i {
tree[max], tree[i] = tree[i], tree[max]
Heapify(tree, fn, len, max)
}
}
type Tree[T any] struct {
item []T
fn func(x, y T) bool
}
func New[T any](fn func(x, y T) bool, v ...T) Tree[T] {
var tree Tree[T]
tree.fn = fn
tree.item = v
Build(tree.item, tree.fn, len(tree.item))
return tree
}
func (h *Tree[T]) Put(e T) {
h.item = append(h.item, e)
Build(h.item, h.fn, len(h.item))
}
func (h *Tree[T]) Peek() *T {
return &h.item[0]
}
func (h *Tree[T]) Poll() *T {
element := &h.item[0]
h.item = h.item[1:]
Build(h.item, h.fn, len(h.item))
return element
}
func (h *Tree[T]) Size() int {
return len(h.item)
}实现定时器模块
定时器模块在服务端开发中非常重要,一个高性能的定时器模块能够大幅度提升引擎的运行效率,使用heap实现一个通用的定时器模块,当然也可以使用队列实现或者链表,但是添加删除任务时间复杂度会很高。
对于链表有所了解的小伙伴,应该都知道以下两点:
- 虽然,取出链表首节点的时间复杂度是
O(1); - 但是,当需要向链表中添加新的定时任务时,保持整个链表有序的时间复杂度是
O(N)。
因此,当定时任务比较多,基于链表实现的定时器就会降低整个服务器的性能,所以使用堆更合适,下面是定时器调度源代码实现:
package timer
import (
"container/heap" // Golang提供的heap库
"fmt"
"os"
"runtime/debug"
"sync"
"time"
)
const (
MIN_TIMER_INTERVAL = 1 * time.Millisecond // 循环定时器的最小时间间隔
)
var (
nextAddSeq uint = 1 // 用于为每个定时器对象生成一个唯一的递增的序号
)
// 定时器对象
type Timer struct {
fireTime time.Time // 触发时间
interval time.Duration // 时间间隔(用于循环定时器)
callback CallbackFunc // 回调函数
repeat bool // 是否循环
cancelled bool // 是否已经取消
addseq uint // 序号
}
// 取消一个定时器,这个定时器将不会被触发
func (t *Timer) Cancel() {
t.cancelled = true
}
// 判断定时器是否已经取消
func (t *Timer) IsActive() bool {
return !t.cancelled
}
// 使用一个heap管理所有的定时器
type _TimerHeap struct {
timers []*Timer
}
// 让内置heap实现sort
func (h *_TimerHeap) Len() int {
return len(h.timers)
}
// 使用触发时间和需要对定时器进行比较
func (h *_TimerHeap) Less(i, j int) bool {
//log.Println(h.timers[i].fireTime, h.timers[j].fireTime)
t1, t2 := h.timers[i].fireTime, h.timers[j].fireTime
if t1.Before(t2) {
return true
}
if t1.After(t2) {
return false
}
// t1 == t2, making sure Timer with same deadline is fired according to their add order
return h.timers[i].addseq < h.timers[j].addseq
}
func (h *_TimerHeap) Swap(i, j int) {
var tmp *Timer
tmp = h.timers[i]
h.timers[i] = h.timers[j]
h.timers[j] = tmp
}
func (h *_TimerHeap) Push(x interface{}) {
h.timers = append(h.timers, x.(*Timer))
}
func (h *_TimerHeap) Pop() (ret interface{}) {
l := len(h.timers)
h.timers, ret = h.timers[:l-1], h.timers[l-1]
return
}
// 定时器回调函数的类型定义
type CallbackFunc func()
var (
timerHeap _TimerHeap // 定时器heap对象
timerHeapLock sync.Mutex // 一个全局的锁
)
func init() {
heap.Init(&timerHeap) // 初始化定时器heap
}
// 设置一个一次性的回调,这个回调将在d时间后触发,并调用callback函数
func AddCallback(d time.Duration, callback CallbackFunc) *Timer {
t := &Timer{
fireTime: time.Now().Add(d),
interval: d,
callback: callback,
repeat: false,
}
timerHeapLock.Lock() // 使用锁规避竞争条件
t.addseq = nextAddSeq
nextAddSeq += 1
heap.Push(&timerHeap, t)
timerHeapLock.Unlock()
return t
}
// 设置一个定时触发的回调,这个回调将在d时间后第一次触发,以后每隔d时间重复触发,并调用callback函数
func AddTimer(d time.Duration, callback CallbackFunc) *Timer {
if d < MIN_TIMER_INTERVAL {
d = MIN_TIMER_INTERVAL
}
t := &Timer{
fireTime: time.Now().Add(d),
interval: d,
callback: callback,
repeat: true, // 设置为循环定时器
}
timerHeapLock.Lock()
t.addseq = nextAddSeq // set addseq when locked
nextAddSeq += 1
heap.Push(&timerHeap, t)
timerHeapLock.Unlock()
return t
}
// 对定时器模块进行一次Tick
// 一般上层模块需要在一个主线程的goroutine里按一定的时间间隔不停的调用Tick函数,从而确保timer能够按时触发,并且
// 所有Timer的回调函数也在这个goroutine里运行。
func Tick() {
now := time.Now()
timerHeapLock.Lock()
for {
if timerHeap.Len() <= 0 { // 没有任何定时器,立刻返回
break
}
nextFireTime := timerHeap.timers[0].fireTime
if nextFireTime.After(now) { // 没有到时间的定时器,返回
break
}
t := heap.Pop(&timerHeap).(*Timer)
if t.cancelled { // 忽略已经取消的定时器
continue
}
if !t.repeat {
t.cancelled = true
}
//必须先解锁,然后再调用定时器的回调函数,否则可能导致死锁!!
timerHeapLock.Unlock()
runCallback(t.callback) // 运行回调函数并捕获panic
timerHeapLock.Lock()
if t.repeat { // 如果是循环timer就把Timer重新放回heap中
// add Timer back to heap
t.fireTime = t.fireTime.Add(t.interval)
if !t.fireTime.After(now) {
t.fireTime = now.Add(t.interval)
}
t.addseq = nextAddSeq
nextAddSeq += 1
heap.Push(&timerHeap, t)
}
}
timerHeapLock.Unlock()
}
// 创建一个goroutine对定时器模块进行定时的Tick
func StartTicks(tickInterval time.Duration) {
go selfTickRoutine(tickInterval)
}
func selfTickRoutine(tickInterval time.Duration) {
for {
time.Sleep(tickInterval)
Tick()
}
}
// 运行定时器的回调函数,并捕获panic,将panic转化为错误输出
func runCallback(callback CallbackFunc) {
defer func() {
err := recover()
if err != nil {
fmt.Fprintf(os.Stderr, "Callback %v paniced: %v\n", callback, err)
debug.PrintStack()
}
}()
callback()
}小结
好了上面对比了各种结构实现的定时任务调度器优越性,也带着使用堆实现一个版本,也说明了为什么使用堆去做,并且解决问题。

