大多数开发者或多或少都使用过 Java 这门编程语言,Java 这门编程语言最大的特性就是一次编写到处运行,这就使得开发者在编写了 Java 源代码之后通过 Java Compiler 编译出来的程序就可以在不同平台架构上运行。不管是 x86 还是 ARM 的 CPU 都运行正常无误,熟悉计算机 CPU 架构都知道不同 CPU 核心使用的不同架构和指令集,如果想要编写一次程序到处运行那就得需要使用交叉编译来完成,但是 Java 打破这一点,这得益于 JVM 的存在,Java 源代码不是将源代码直接编译成为对应平台机器码,而是自己定义一套指令集规则也就是对应的 Java Bytecode 标准,再通过将其字节码文件放到 JVM 上运行,最终 JVM 充当一个翻译员将其通过 JIT 的方式运行程序。
Java 跨平台原理
编写 Java 程序的源文件都是以 .java 为后缀名的文件,下面则为一个 Java 源代码文件要想运行它必须通过 Java 编译器来生成对应的字节码 .class 文件,从而让不同平台的 JVM 加载 .class 文件来运行程序:

这里值得注意的是 Java 现在每 6 个月就有一次更新,每次都会有新的语言特性添加,不同版本的 Java 编译器可能生成的代码文件在不同 JVM 有不同效果,例如低版本的 JVM 不能运行高版本的 Java 编译器生成的 .class 文件,反过来则是可以的,不过这些都是小问题可以通过 AOT 编译成对应平台机器码运行,也可以使用一些第三方提供程序版本代码迁移工具 EMT4J 来完成。
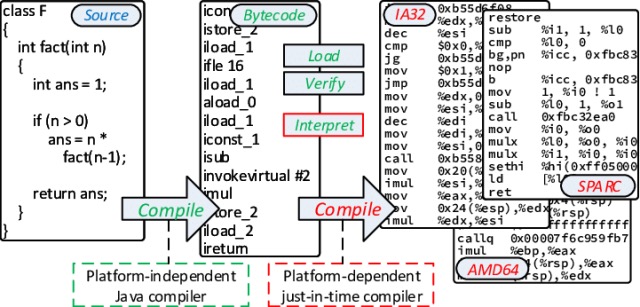
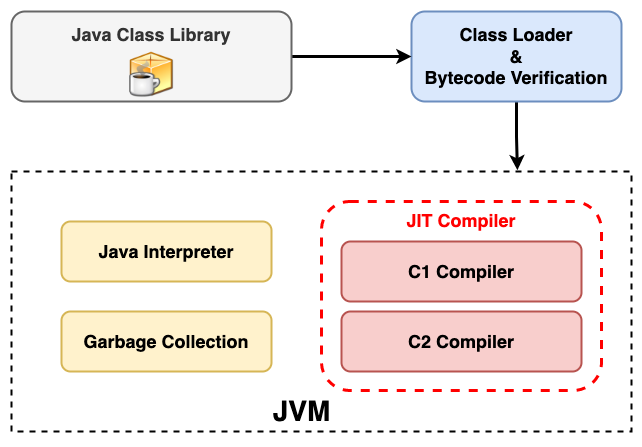
在 JDK 整个开发工具包中其实有两套编译器,大多数程序员所使用的 javac 编译器,此编译器只是将编写的 java 源文件编译生成为 JVM 能认识的字节码;而在 JVM 中又有一套 JIT 编译器,针对的是更高性能程序场景使用的,会把字节码再次编译成为机器码。
JVM 主体架构
当 Java 程序需要运行的时,此时就得需要 JVM 了,JVM 内部大致会和下图接近,首先前面通过 Java Compiler 生成的 .class 文件会把加载到虚拟机内存中,首先头一次执行是通过 JVM 内置 Interpreter 解析执行代码,这个过程 JVM 的解析器会把字节码里面指令翻译成对应平台的指令进行运行。
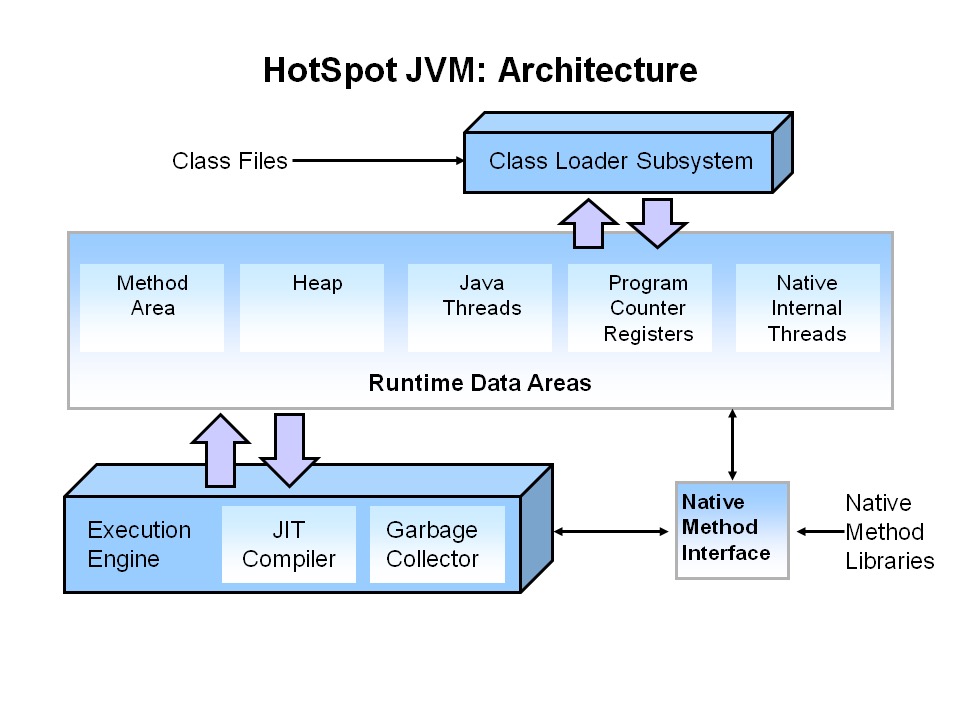
另外 JVM 中内置另外 2 个 JIT Compiler 分别为 C1 和 C2,这两个即时编译器是针对长时间运行的热点代码进行优化的编译器,JVM 的设计者在设计的就考虑到一些程序代码运行效率的问题,前面提到的通过解析器执行代码性能肯定不能和 C 这种原生编译成机器码的程序性能相比,所以设计者针对热点代码会采用 C1 和 C2 编译器进行编译较为底层次的机器码来执行。
warm 的标签,当某一行代码被执行了很多次,这行代码会被打上 Hot🔥 的标签成为热点代码,这和 JVM GC 分代设计方式类似,通过分代来解决不频繁 GC 放到老年代。
在运行时将热点函数编译为汇编代码,当程序再次运行到经过实时编译的函数时,就可以执行经过编译和优化的汇编代码,而不再需要解释执行了。由于编译是在运行时进行的,因此 JIT 编译器可以获得代码实际运行的路径、热点和变量值等信息,基于此可以做出非常激进的编译优化,从而获得执行效率更高的代码。何为热点代码?例如下面有一段代码就为热点代码,当然现实中程序热点代码可能更为复杂:
public class HotSpotExample {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
int iterations = 100000000;
for (int i = 0; i < iterations; i++) {
// 热点代码块
int result = compute(i);
if (result % 2 == 0) {
System.out.println("Even");
} else {
System.out.println("Odd");
}
}
long endTime = System.currentTimeMillis();
System.out.println("Time taken: " + (endTime - startTime) + " ms");
}
// 模拟一个计算函数,这里只是一个简单的示例
private static int compute(int input) {
return input * 2 + 1;
}
}在这个示例中 HotSpot 编译器会观察程序的运行情况,当 compute 方法被多次调用后,它会优化这个方法的执行,将其编译为本地机器代码,以提高执行效率。C1 编译器优化较少,但是编译所消耗资源也较少;C2 编译得到的代码性能最好,但是编译消耗的资源也较多,但是目前在新版本的 JDK 中采用了 Graal 替代了 C2,新版本的 Graal 采用的是 Java 编写,因为是 Java 某些方面能做出的优化比 C2 要强,C2 编译器是使用 C++ 编写的难以维护并且某些特性实现不了,例如函数的局部逃逸分析的优化上,这样也是 Oracle 官方的将其 JVM 命名为 Hotspot Virtual Machine 原因。
JVM 核心组件
当 JVM 被启动它所做的工作就是为 .class 服务,跑起来是一个进程会加载 jar 包或者 war 包,这里的 war 包是基于 Servlet 容器的,例如 Tomcat 容器,这些容器本身也是 Java 程序也是跑在 JVM 进程之上的,当不同请求过来会被 JVM 内部的线程进行调度,下面为 JVM 内部结构主要架构图:
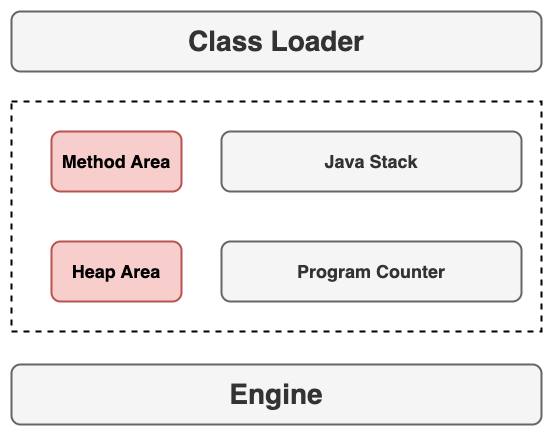
当 JVM 开始执行 Java 程序时,会找到程序入口 main 方法并且创建一个线程开始执行,也称之为主线程;如果在类中创建了其他对象内存会被分配到 Heap 中;当运行一个函数时此时就需要每个线程的执行栈,函数都在自己的栈空间里执行,栈空间里存储的是运行时产生的局部变量,当线程执行到那一条字节码指令时,这个信息指令会被存放在程序计数寄存器中。
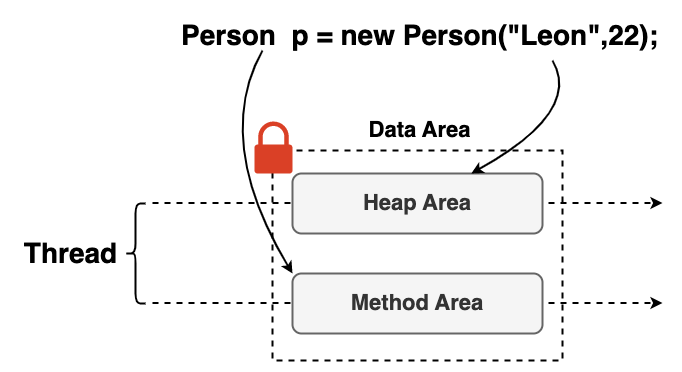
在程序中有一部分内存是在执行过程中可以被多个线程共享的,例如 Heap 内存,在 JVM 中的 方法区 和 堆 的内存都是可以被共享的。这样就会使得多个线程能访问该区域的内存数据,只要涉及到共享数据就产生数据竞争问题,在编写 Java 程序同样要考虑的这些多线程数据竞争问题,如果了解 JVM 这些内部组件的关系就可以使得编写代码时能够避免一些数据竞争的问题。
JVM 的字节码中程序执行依靠着栈,JVM 实现的指令执行都是依靠着栈结构来设计的,和传统的直接面向 CPU 硬件指令寄存器不一样。因为 JVM 作为一层物理机器抽象层必须要适配很多不同架构的 CPU ,所以如果使用寄存器的架构就必须和本机的平台架构绑定到一起;而 JVM 基于栈的实现可以在多个不同硬件平台上执行程序,但是基于栈指令比基于寄存器的指令要多,传统寄存器只需要 2 条指令完成的操作,而基于栈的可能需要多个指令操作,下面为一个计算两数之和的 Java 源代码对应的字节码指令:

当字节码指令被执行时,JVM 中的 Program Counter Register 就会保存着每个线程栈该执行对应字节码指令的位置地址。在多线程环境下 CPU 具体如何去调用这些线程是不确定的,线程之间是可以来回切换的,如果发生了切换线程操作,当线程被切换到 CPU 上继续执行时就可以从 PC 中获取对应指令地址;在每次执行一次字节码指令之后 PC 的值会对应将其加指令地址操作,具体增加多少的得看指令大小偏移量,此时 PC 就会保存着下一条需要被 JVM Engine 执行的字节码指令的地址。下图为执行大致的过程:

栈是在运行时的单位,而堆是存储的单位,当程序被执行起来时每个线程都有相应的栈,对象和方法最后都是为字节码指令会被依次压入栈中进行操作,在栈顶的栈帧为正在执行的栈帧,当栈帧上栈帧被执行完成之后会销毁,依次执行直到栈为空程序结束执行。
在栈中的变量所使用的内存是不需要被 Garbage Collection) 所管理的,当栈帧销毁时变量所使用的内存就会被释放掉,这里针对的是基础数据类型 byte 、 short 、 int 、long 、float 、 double 、 char 、boolean 所分配的空间,而针对的自定义复合数据类型 Class 在使用时就被称之为引用类型,当使用 new 关键字创建对象时此时它所占用内存是在堆上分配,而在栈上也就是一个指向堆的内存地址引用,内存布局为下图:
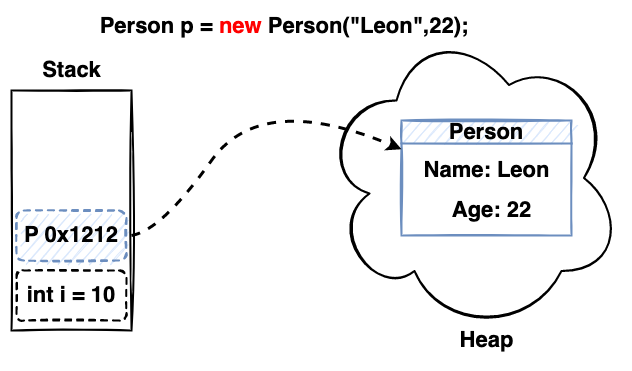
当在不同的方法之间传递对象的时,对象的信息会在每个方法栈中,传递依靠着是局部变量表,局部变量表是 JVM 设计一个特殊的表格,会有 slot 槽位,槽位中存储的各个变量在栈帧中的信息,可以根据这些信息找到对应分配空间,例如在栈帧中操作堆内存上的数据。局部变量表的大小会影响的栈帧的大小,如果局部变量表很大的话可能会占用更多空间,而相应的能创建栈帧数就会减小,局部变量表还有重要的作用就是和垃圾回收相关的,它是垃圾回收器扫描时的根节点,如果局部变量表中的变量还在被使用,这个变量所占用的内存就不会被回收掉。
垃圾回收
前面介绍 JVM 内存部分了解到程序在运行过程中会不断的创建新的类对象,每个的对象都需要内存分配,而这些内存会从堆内存中分配,如果频繁的不断创建对象很有可能导致堆内存被占用满。计算机的内存不是无限的这时 JVM 的设计就要想办法收回一些不再使用的对象占用的内存空间,这里将不再使用的对象称之为垃圾,所谓的垃圾就是不再使用的对象引用,垃圾回收器核心功能就要找出存在堆中不再被使用的对象,清理掉占用的空间,再让这些空间再被二次使用。
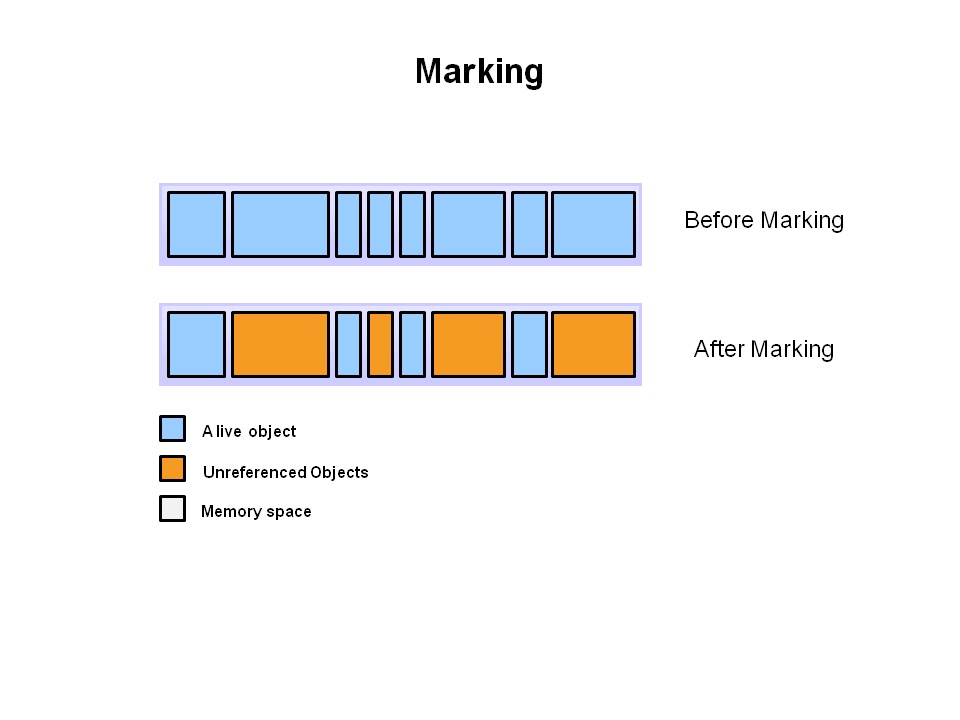
目前在很多自动回收内存的编程语言中,都有垃圾回收器算法的踪影,这个取决于各种的垃圾回收器算法的实现大同小异,常见的垃圾回收器分为 3 种:
- 串行垃圾回收器: 每当垃圾回收器的线程工作的时候,所有正在执行其他计算任务的线程必须停止工作,如果不停止其他线程会导致垃圾回收器标记的垃圾会引发混乱,当这些线程被停止之后就会引发程序停止的状态,这个过程也称之为 STOP THE WORLD 即世界被暂停了。
- 并行垃圾回收器: 相较于串行垃圾回收器的工作方式稍微做了一些优化,采用多个垃圾回收器线程工作的方式进行垃圾扫描标记和清理工作,可以利用多核 CPU 的优势提高整个垃圾回收过程效率。
- 并发垃圾回收器: 这种垃圾回收工作线程和其他计算任务线程可以并发的运行,我称之为渐进式垃圾回收算法,这和前面我博文中讲到的 Wisckey存储 扫描标记的方式类似,先对某块内存进行扫描划分区域性扫描,渐进式扫描整个堆空间直到完成。
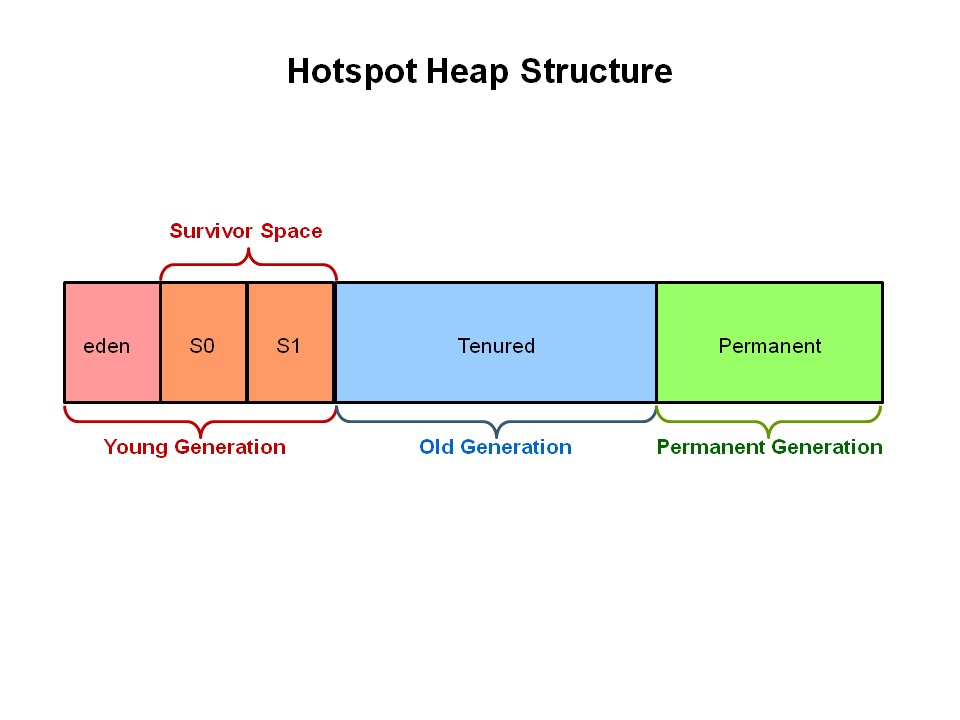
上图为 JVM 中的堆结构内存布局,JVM 的内存布局采用的分区的方式,分为新生代和老年代两种堆区域,这种分区的方式和执行引擎中针对热点的代码的方式很类似,如果某些代码被频繁的执行就会被进一优化成底层机器码。而 JVM 中堆内存布局也有这种设计方式,绝大多数的 Java 对象的生命周期一般都很短,对应这种对象都是归于新生代区域管理,垃圾回收器针对于新生代的堆空间 GC 可能比较频繁,但是不会去扫描整个堆区域的内存,从而提高 GC 效率。
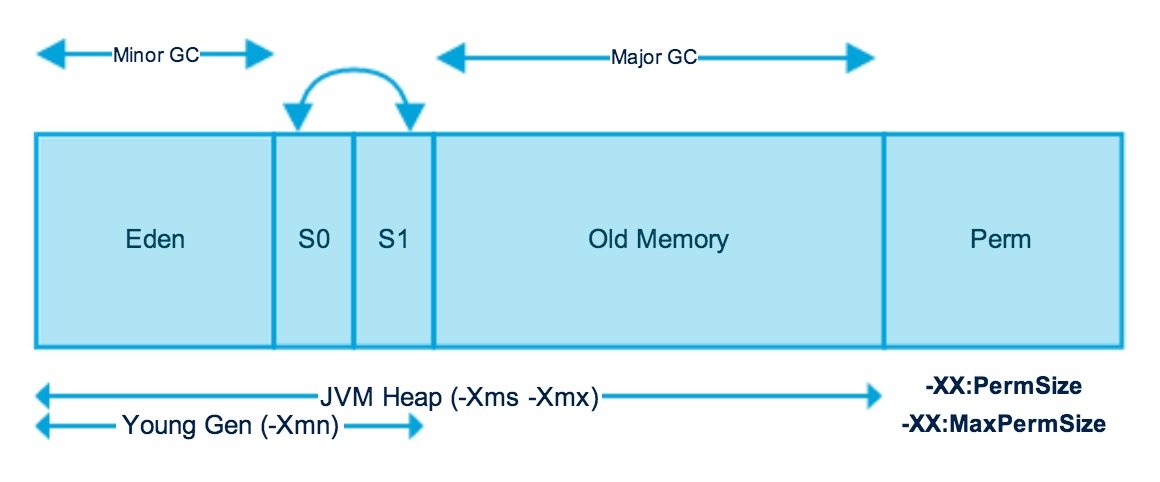
当年轻一代填满时,这会导致一次小的垃圾收集过程,假设年轻代区域的对象死亡率很高,就可以进行一次小规模的垃圾清理过程,在此过程中一些幸存的对象会老化并最终移至老年代,进行这样的一次过程被称之为 Minor GC。而老年代中则存放的存活时间较长的对象,长期存活的对象与经过多次 Minor GC 依然存活下来的对象,在老年代内存被占满时就会进行垃圾回收,而老年代进行垃圾回收过程称之为 Major GC 这个过程可能相较于 Minor GC 执行时间更长。
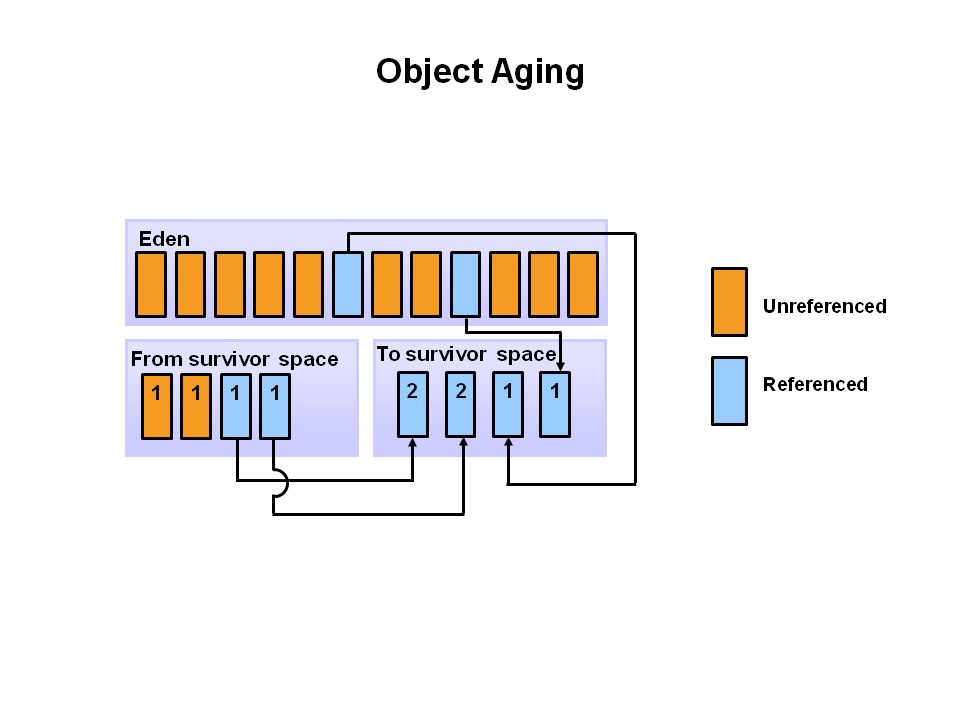
新生代设计较为复杂,本分为了 3 个不同的区域分别为 Eden 和 S0 、S1 三个区域,Minor GC 会先扫描整个 Eden 区域如果有未引用的对象,会直接清理掉,而针对还有被引用的对象则会被移动复制到幸存者空间 S0 中。这样反复 Minor GC 之后如果还会存活,一旦所有幸存的对象都被移动到 S1,最后会直接移动到老年代上,新生代整个区域将会被清理掉。
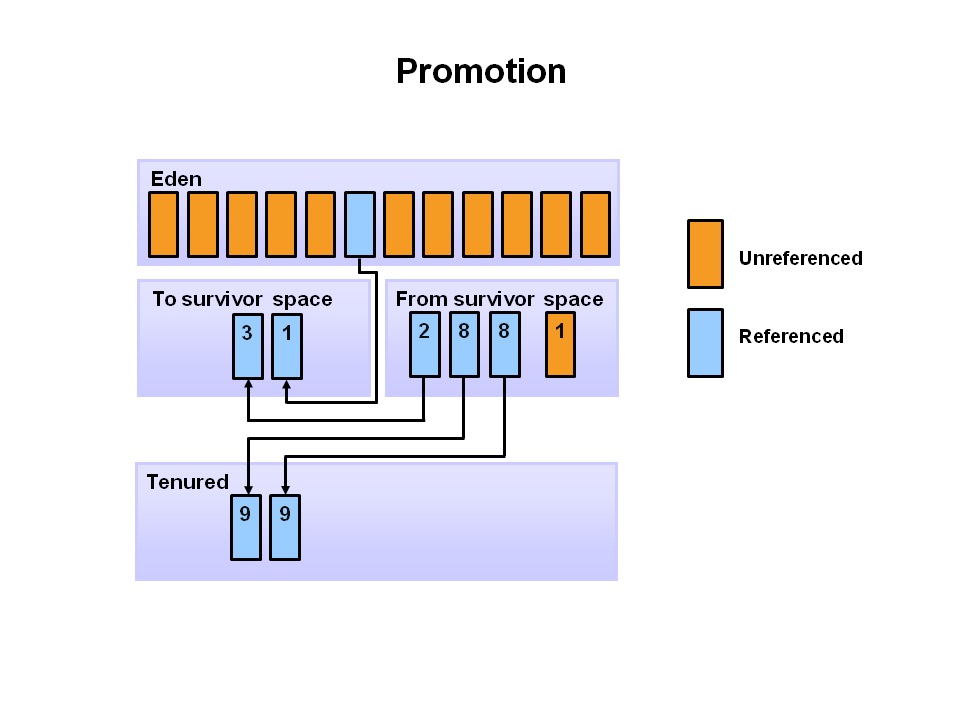
当数轮次要 Minor GC 之后当老化的对象达到某个年龄阈值时,它们会从年轻代提升到老年代,最终将对老年代执行主要 Major GC ,清理并压缩该空间,这就是整个 JVM 的垃圾回收器设计,通过分代的方式进行垃圾回收器清理这和 LSM-Tree 存储引擎的垃圾回收器的设计有很相似之处,非常精妙!最后永久代包则含 JVM 所需的元数据用于描述应用程序中使用的类和方法,由 JVM 在运行时根据应用程序使用的类填充,此外 JavaSE 的标准库类和方法可能存储在这里。
Summary
作为一名 Java 开发人员了解 JVM 相关的原理对于编写健壮的 Java 程序有很多帮助,当然 JVM 也不止适用于某个特定的编程语言,了解 JVM 也是帮助提升对计算机底层技术的认知,在 JDK 中包含了很多用于调式 JVM 的工具,例如查看内存情况的 jmap 和 垃圾回收器状态的 jstat 工具,还有一个单独的 VisualVM 项目,这些都是官方提供好的工具能帮助开发者在实际开发中解决问题,了解 JVM 架构之后当程序出现问题了之后就知道从哪里入手解决问题,不会出现束手无策的情况。
其他资料
- What Does a Modern JVM Look Like, And How Does It Work?
- GraalVM + AWS Lambda or solving Java cold start problem
- AOT vs. JIT Compilation in Java
- Deep Dive Into the New Java JIT Compiler – Graal
- Categories of Java HotSpot VM Options
- Java Language and Virtual Machine Specifications
- Java | Multithreading Part 1: Java Memory Model
- Java Garbage Collection Basics
- Minor GC vs Major GC vs Full GC
- OpenJDK vs. Dalvik/ART Virtual Machine
- Java Developer's Introduction to GraalVM / 郑雨迪
- 浅析JAVA虚拟机结构与机制
- CORE JAVA WEEK 2022 | 面向云原生现代化Java实践与演进-李三红

