什么是结构化并发?日常开发中我们编写的最多就是多线程程序,服务器端应用更是如此,传统的方式都是依靠着操作系统提供的 1:1 线程方式进行请求处理这对于管理和复用线程有很多挑战,如果一个普通线程大小 8MB 那么开启 1000 个线程,几乎是无法完成的,并且管理这些线程的状态也是很复杂的。今天这篇文章要介绍的是结构化并发,就是为解决并发编程中线程并发任务管理,传统的方式非常容易造成管理混乱。结构化并发解决的问题就是对统一的任务和统一作用域下的任务进行管理,可以统一启动和统一关闭,如果读过我之前的 Linux 进程组那篇文章的话,就完全可以理解是什么意思了,文章地址:Linux 进程树。
在了解结构并发编程范式之前得先讲讲编程语言流程控制发展史,了解一件事的全部应该是去了解完整的历史,并且要找到正确的资料和原版资料去了解,而不是已经修改几个版本的资料,让我们回顾编程语言的一些历史:早期如果想在计算机上写程序必须使用很低级的编程语言去写程序,例如汇编语言,通过一条一条硬件指令去操作计算机,并且顺序执行的,这种编写程序的方式真是令人头疼的。这就使一些计算机界大佬想去重新设计一些编程语言,当时一些美籍计算机科学家们 John Warner Backus 和 Grace Hopper 开发了 Fortran 和 FLOW-MATIC初代的编译命令式编程语言,最后在这些基础之上开发了商业通用编程 COBOL 语言。
有趣的事情是世界上的第一个 Bug 也是 Grace Hopper 所发现的,当时的计算机(Harvard Mark II)体积还很大。当时这台计算机在运算的时候老是出现问题,但是经过排查编写的程序指令是没有问题的,最后发现原来是一只飞蛾意外飞入电脑内部的继电器而造成短路如下图所示,他们把这只飞蛾移除后便成功让电脑正常运作,这就是世界上第一个计算机程序BUG。

早期的 FLOW-MATIC 是第一种使用类似英语的语句来表达操作的编程语言,会预先定义输入和输出文件和打印输出,分为输入文件、输出文件和高速打印机输出,下面是一段程序代码的例子:
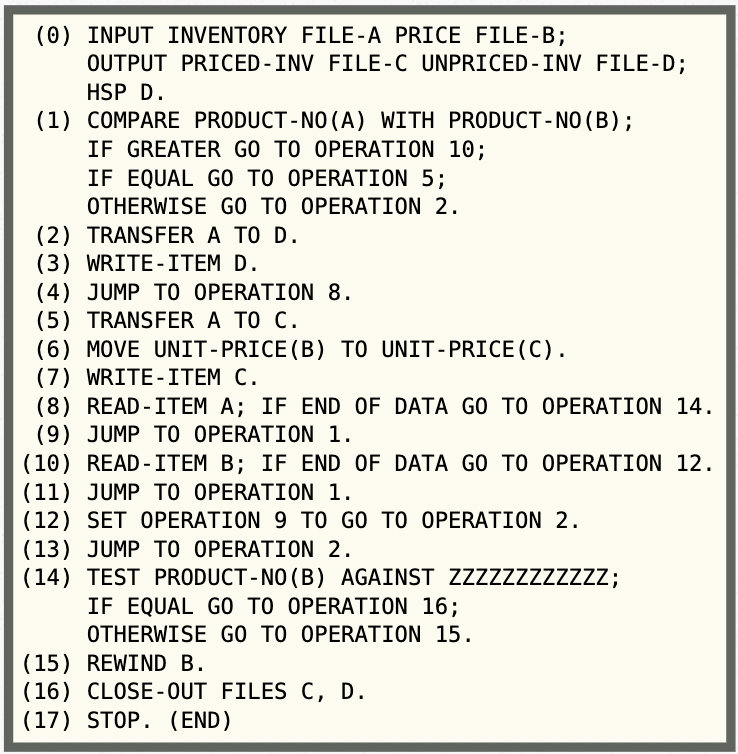
看完上面的实例,会发现和现在开发者所使用的更高级的 Java 或者 C 语言还是有一些差距的,例如没有函数代码块,没有条件控制语句,在 FLOW-MATIC 被推出的时候这些现在高级语言的特性还没有被发明出来,在当时看来 FLOW-MATIC 应该是能满足编写程序需求。
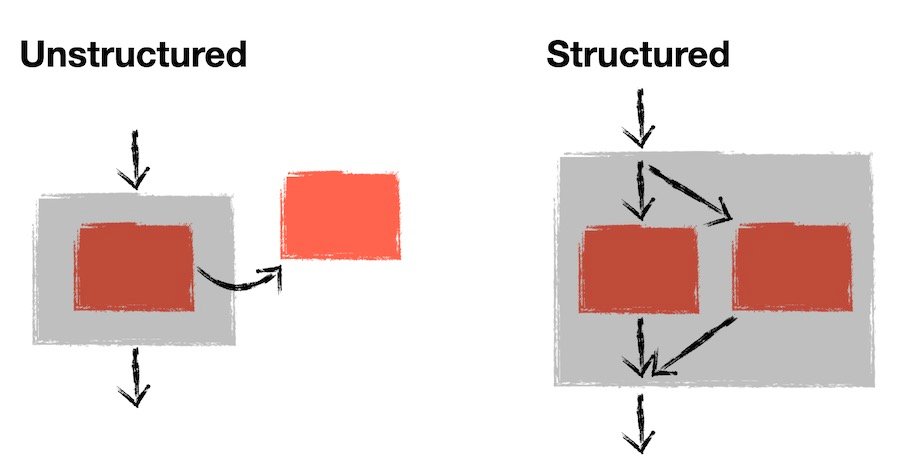
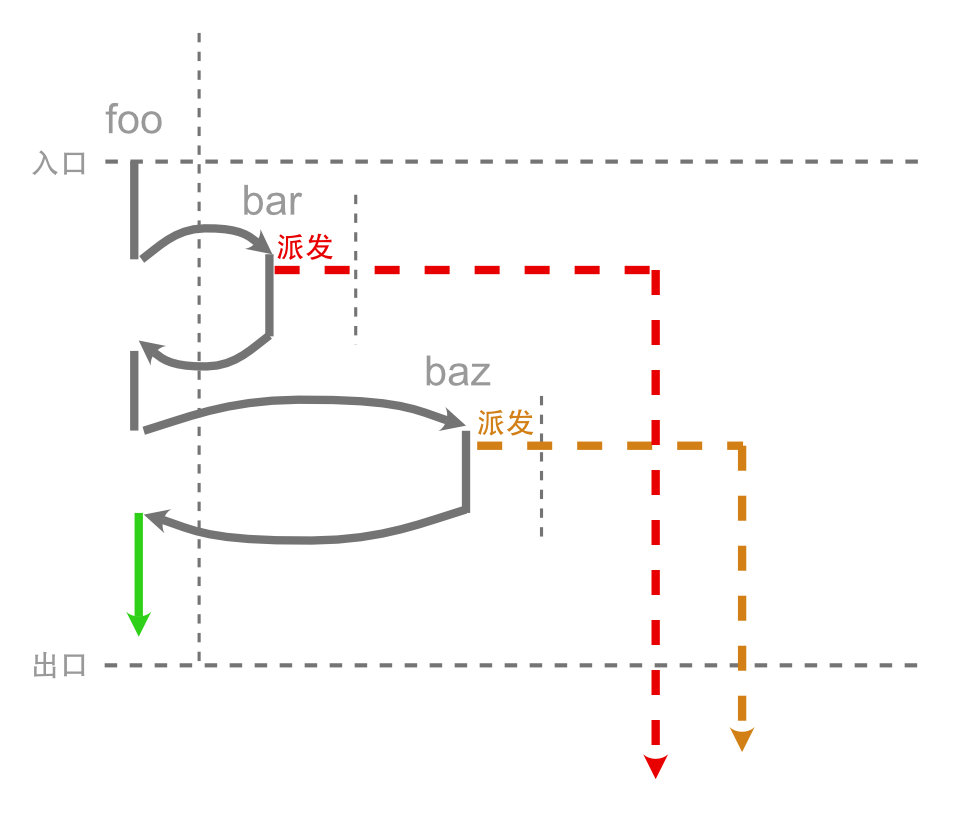
设想一下如果和输入指令一条一条执行程序是不是很麻烦,如果不能复用一些以有编写逻辑那就要重新编写一些代码逻辑会很费时费力,所以 FLOW-MATIC 的设计者在语言加入了 GOTO 语句块, goto 可以让程序在执行的时候执行到了 goto 然后去执行指定位置的代码块,本质上还是非结构化编程,不过可以做到程序的代码复用和重执行, goto 的加入 FLOW-MATIC 之后如下程序执行流程图:
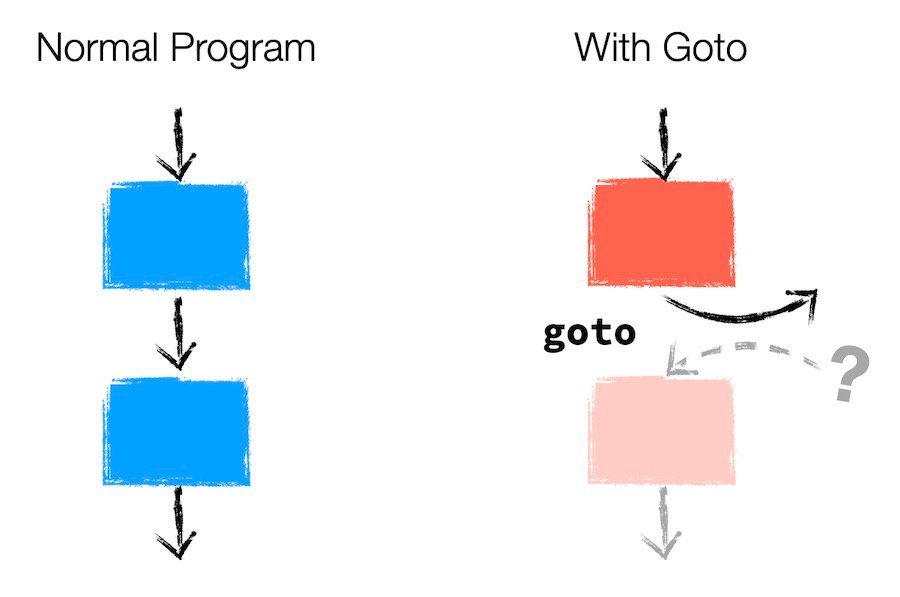
FLOW-MATIC 执行语句通常都是顺序执行的,但是下面这种情况就会发生跳转操作,它可以直接将控制权转移到其他地方,例如下面从 8 行跳转到第 4 行。

极少量的 goto 语句是很清晰的,但是令人头疼的问题是程序代码逻辑量变多了之后就会产生很多无法通过正常人类思维所理解的代码跳转逻辑,并且跟踪代码的逻辑很困难。这种基于跳转的编程风格是 FLOW-MATIC 几乎直接从汇编语言继承而来的。它功能强大,非常适合计算机硬件的实际工作方式,但直接使用它会非常混乱。像上面图片中的箭头箭头太多了,就发明 Spaghetti Code 一词的原因,代码逻辑存在各种飞线关系,揉成一坨的代码逻辑。显然我们开发者需要更好的流程控制设计,而不是让代码逻辑写出来像意大利面条一样。

当然目前讨论的话题是编程语言的结构化编程设计问题,这个不是本篇文章的重点,本篇文章更偏向的是一些编程语言在线程并发状态转播和控制管理上的一些问题,下面正式开始正文内容。
非结构化并发
介绍了早期编程语言中的 goto 关键字,可以在当前的执行控制流中开一个分支去执行另外的操作,和我们现在在高级编程语言中使用的 Thread 差不多,例如下面代码:
package main
import (
"fmt"
"time"
)
func f(from string) {
for i := 0; i < 3; i++ {
go fmt.Println(from, ":", i)
}
}
func main() {
f("direct")
go f("goroutine")
go func(msg string) {
fmt.Println(msg)
}("going")
time.Sleep(2 * time.Second)
fmt.Println("done")
}在线运行代码地址: https://go.dev/play/p/wQ7Yz9mxXlu
在这个例子中我使用的是 Go 语言的 goroutine 为例,在 Go 语言中想启动一个协程就可以使用 go 关键字,这和上面我们讨论的 goto 语句很接近,会从主控制流中分离出另一个代码逻辑执行分支,流程如下图:
当然在 Go 语言中是保留 goto 跳转语句块的,例如下面这行代码就是 Go 中的 goto 语句块:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* 循环 */
LOOP: for a < 20 {
if a == 15 {
/* 跳过迭代 */
a = a + 1
goto LOOP
}
fmt.Printf("a的值为 : %d\n", a)
a++
}
}在这个例子中 goto 代替了传统的 break 关键字的作用,那个例子准确来说应该是说类似于 continue 作用,看怎么用了,这里不接受任何反驳。直接跳过满足 a==15 的逻辑块。这就是目前高级语言中的跳转应用,当前这种还是在主程序流上运行的指令的,于 Go 语言中的 go func(){} 关键字去跑起一个协程做并行任务处理是完全不一样的,为此我特定花了一张图来比较两者的关系,如下:
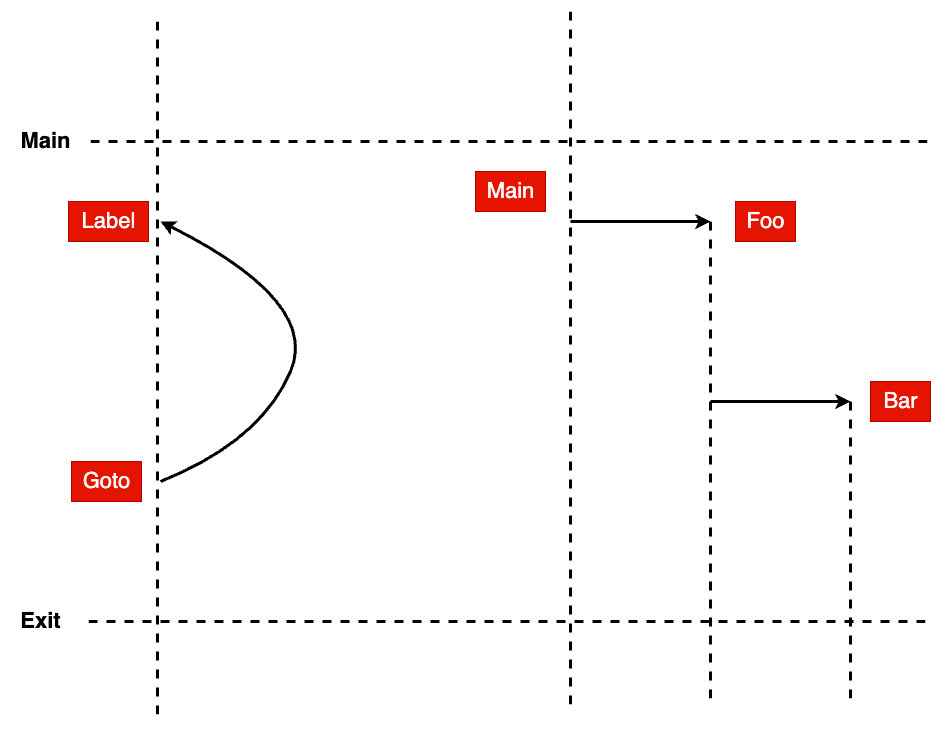
像上面这样的通过 go 关键字启动的协程就和一个不透明的盒子一样,你不知道被启动代码块里面是否还有 go 关键字启动其他协程,递归启动协程是一件很难控制的事件,这就和 MapReduce 思想很像,最终还是要汇总的每个协程中产生的数据和控制协程状态的,如下图:
像上面这幅图中如果里面的每个圆圈 ⭕️ 都代表着一个正在并行处理任务的协程,我们要如何管理这些协程状态呢?当然 Go 语言在设计的时候就引入了 channel 概念,我们开发者可以显示将 channel 提供代码的方式嵌入到每个要执行协程任务代码块中;早期的 Go 版本中为了控制协程中的协程状态是直接嵌入 channel 然后再每个协程内部编写具体状态控制代码,如果上级发送了通知那么此协程会做出相应的动作,这是初步的 Go 版本状态控制。
在最新 Go 语言设计的版本中为了管理这些协程,在语言默认标准库中通过了 context 包所提供功能来做并行协程上下文通讯和状态同步:
package main
import (
"context"
"fmt"
"time"
)
func doSomething(ctx context.Context) {
ctx, cancelCtx := context.WithCancel(ctx)
printCh := make(chan int)
go doAnother(ctx, printCh)
for num := 1; num <= 3; num++ {
printCh <- num
}
cancelCtx()
time.Sleep(100 * time.Millisecond)
fmt.Printf("doSomething: finished\n")
}
func doAnother(ctx context.Context, printCh <-chan int) {
for {
select {
case <-ctx.Done():
if err := ctx.Err(); err != nil {
fmt.Printf("doAnother err: %s\n", err)
}
fmt.Printf("doAnother: finished\n")
return
case num := <-printCh:
fmt.Printf("doAnother: %d\n", num)
}
}
}本示例代码在线地址:How To Use Contexts in Go
关于结构化并发在 Go 语言中一些问题上面是我个人见解,还有一些关于 Go 中的结构化并发讨论的文章可以查看这篇文章:Go statement considered harmful,在这篇文章里面作者对现有的Go语言协程设计抛出很多观点值得一读。
结构化并发设计
在上面我介绍了一些关于非结构化并发的程序设计问题,如果单独创建协程没有做好错误处理或者异常情况下的处理,可能就会出现协程泄露问题,这就是本节要讲的结构化并发来做的并发控制设计。
这里我会拿我目前还稍微熟悉一点的 Java 语言举例,例如在 Java19 中添加的结构体并发特性,所采用的线程控制就是结构化并发的应用,如下的示例代码:
void serve(ServerSocket serverSocket) throws IOException, InterruptedException {
try (var scope = new StructuredTaskScope<Void>()) {
try {
while (true) {
var socket = serverSocket.accept();
scope.fork(() -> handle(socket));
}
} finally {
// If there's been an error or we're interrupted, we stop accepting
scope.shutdown(); // Close all active connections
scope.join();
}
}
}上面代码的逻辑就是一个简单的 socket 处理逻辑,采用的就是结构化并发,可以看到 finally 里面的异常处理逻辑和 scope 任务线程块,当然这些内容在 Oracle 公司的 Open JDK 设计草案里面就有地址如下:https://openjdk.org/jeps/428,我只是对这篇内容做了导读和个人见解分享,当然这里我拿几个语言作为例子不是为了讨论谁好谁坏,而是从语言设计角度来看每个不同语言面对这些问题是怎么解决的,瑕瑜互见。
小结
我个人认为结构化并发是未来的并发和并行程序设计方向,现在有结构化并发程序设计的语言 Kotlin 、Java 、 Swift 等,Rust 语言中也有这方面相关第三方实现目前还不够完善。由此可见通过作用域定义了主协程的子协程的生命周期和关系,事实证明,这一原则在协程中实施了层次结构。如果协程需要为自己创建子协程,那完全没问题,就像您如何将if语句嵌套在一起并理解分支如何嵌套一样,协程也可以嵌套,最顶级的协程不仅取决于他们的孩子完成,还取决于他们孩子的孩子,这就是一个多叉树型的结构,更多相关研究还要靠着开发者们一起探索,我下面给出一些这方面领先的技术文章分享链接。

