大文件排序
现在计算机内存和硬盘容量,都差几个数量级,大数据开发里面大部分接触的数据都是很大的,一些数据可能存储在数据库里面这些排序起来很简单,使用SQL语句SELECT * FROM table_name ORDER BY columu ASC|DESC;就可以完成排序功能,但是也没有想过那么多数据存储在数据库里面,数据库底层数据又是在硬盘上,那么数据库在少量内存怎么对那么多数据进行排序呢?
类似于的问题例如按照年龄给100万个用户进行排序,怎么用少量的内存,进行排序,降低时间复杂度。还有例如有一个超级大的文件,大小为10GB,但是现在计算机内存只要1GB怎么办?
这个就是典型的大文件和大数据在有限的条件下进行排序运算的问题。对于给100万用户进行排序,这些用户的年龄都有很大差值的,大的可能建设为120岁,小的可能为2岁,怎么充分发挥内存利用率?而且这些年龄段的用户分布可能不均匀,有数据量偏差...
当然可以使用桶排序,把数据按照响应的规范存储在数据桶里,每个的桶对应的就是某个数据范围到某数据范围的数据,然后对每个桶内的数据进行排序,然后在总体合并,就可以完成了。
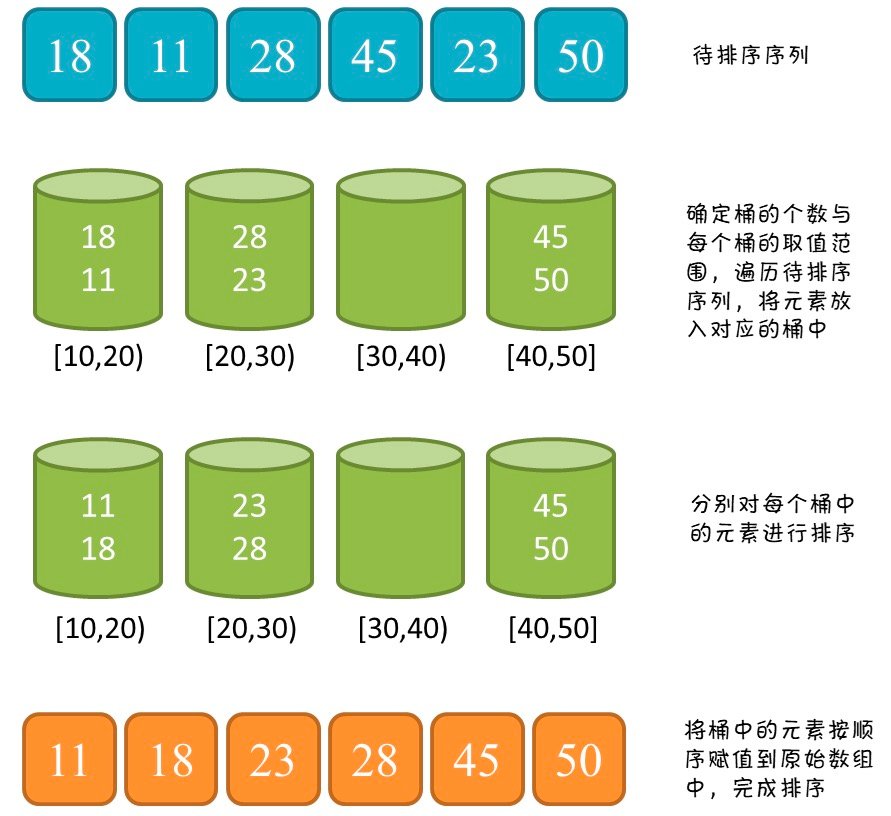
针对数据偏差,可以把数据分解成多个小段数据进行装桶,再排序,降低空间占用。
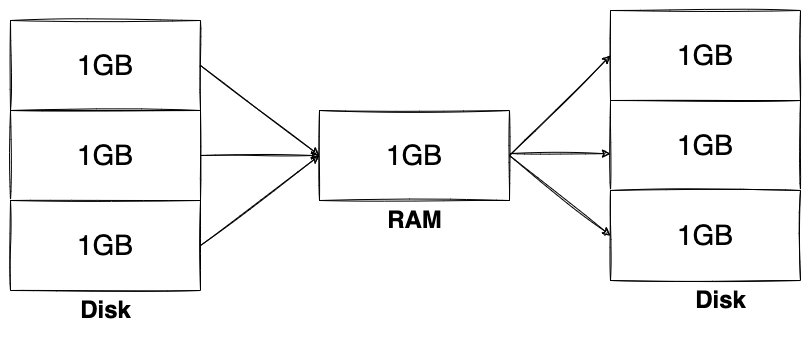
对于一个很大的文件排序,切分成很多个小文件,使得每个小文件能够单独的装进内存,并将每个小文件进行内排序(快速排序等等),然后再将多个小文件进行多路归并排序,最终得到一个有序的文件。
多路归并排序在大数据领域也是常用的算法,常用于海量数据排序。当数据量特别大时,这些数据无法被单个机器内存容纳,它需要被切分位多个集合分别由不同的机器进行内存排序(map过程),然后再进行多路归并算法将来自多个不同机器的数据进行排序(reduce 过程),这是流式多路归并排序。
多路归并排序的优势在于内存消耗极低,它的内存占用和输入文件的数量成正比,和数据总量无关,数据总量只会线性正比影响排序的时间,过程如下图:
计数排序
根据上面的问题,其实计数排序也是使用少量的空间,针对大数据量的数据进行排序,然后再整合输出,思想也是分而治之方法。计数排序问题也是有的,如果多个数据值相同的,不能区分数据前后位置,还有数据桶的大小取决于数据值里面最大哪一个值。例如[90,99,98,95,92,96],如果对这段数据进行排序的话,默认索引(这里的索引使用数组保存)的下标是为0,那么我们的90为最小的数据值,它前面的空间就没有充分利用,因为需要排序的数组里面的数值是从90开始的,0-89这些位置是空的,为了解决这个问题就要引入偏移量,经过偏移量就能确定位置并且还能充分发挥空间利用率。
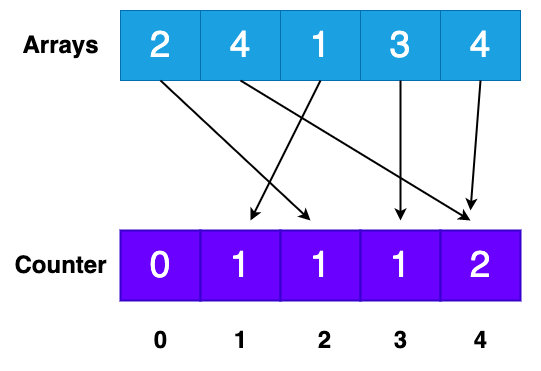
计数排序的原理:对原数组的内容依次遍历,并且拿到其值找到对应的计数数组下标,然后将对应的下标值加一,最后遍历完数组,然后对其计数数组依次遍历输出,计数数组里面的值有多少就输出多少次。
以上是简单的计数排序过程,如果遇到数值区间偏移太大,空间利用率会有问题,并且不能满足重复值的前后顺序,下面是一个升级版的计数排序。
package me.ibyte.sorting;
import java.util.Arrays;
public class Counting {
public static void main(String[] args) {
Integer[] arr = { 22, 11, 34, 111, 1, 453, 5 };
arr = countingSort(arr);
System.out.println(Arrays.toString(arr));
}
// https://segmentfault.com/q/1010000003902641
public static Integer[] countingSort(Integer[] arr) {
int max = arr[0], min = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
if (arr[i] < min) {
min = arr[i];
}
}
// 计数出区间偏移
int offset = max - min + 1;
// 根据区间创建计数数组
int[] counts = new int[offset];
// 对应的下标累加
for (int i = 0; i < arr.length; i++) {
counts[arr[i] - min]++;
}
// 为了保证某个元素之前的位置,就都要累加前面元素的个数
for (int i = 1; i < counts.length; i++) {
// 当前累加前面元素之和
counts[i] += counts[i - 1];
}
// 排序数组,倒序遍历输出元素每次减一
Integer[] sortd = new Integer[arr.length];
for (int i = arr.length - 1; i >= 0; i--) {
sortd[counts[arr[i] - min] - 1] = arr[i];
counts[arr[i] - min]--;
}
return sortd;
}
}

