Go1.18 泛型
最近随着 Go 1.18 版本发布了,也就是 Go 正式支持泛型编程了,这个版本的发布将会给你 Go 编程开发体验带来巨大变动,估计后面一些开源库也会陆续重构,对 Go 语言从发布至今应该是一次最大改动。
Generic Programming
在之前的版本中 Go 语言想做一些通用的数据类型的编程操作的时候,可能大部分还是使用 interface 来进行编程,但是代码里面会出现各种断言操作,并且还有预判出可能需要的数据类型,重复编写一些只是类型不一样的代码块,如下图就是之前在社区里面经常流行一张关于 Go 泛型编程调侃图👇🏻,只是数据参数类型不一样,但是具体逻辑代码又是一样的,会使得开发者我们重复编写一些代码块:

当然之前版本 Go 语言标准库中提供一个 text/template 包,这个包如果开发者自己能力很强可以通过自己写一些代码块,然后通过模板引擎去生成相关的代码,一些第三方的框架代码生成就是这个原理,例如官方的 go generate 命令。
其实泛型编程,可以简单理解毕昇发明的活字印刷术一样,我在编写程序的时候把一些通用的代码逻辑写好,只是可能运行的时候数据类型可能不同而已,只需要开发者定义好预计数据类型,然后其他事情交给 Go 编译器。

我本人也是对 Go 泛型编程也是很期待,在 2020 的时候我在实现一些通用的算法和数据结构时就遇到了一些重复代码逻辑的问题,并且向官方询问过,当时官方给了我一些泛型的设计草案,后面这个草案一直在改动,直到现在终于发布了。
体验一把泛型
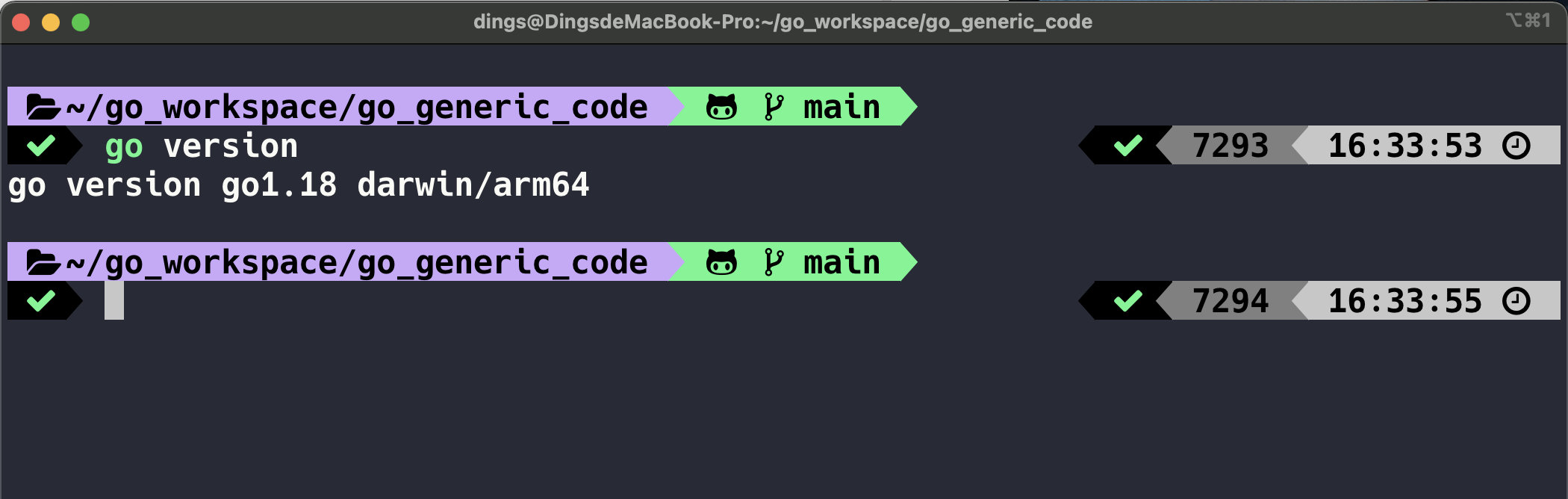
首先需要使用泛型的话,你的 Go 语言版本需要升级到 1.18 这个语义化版本,如下图我已经升级到这个版本了。
下面我写一段冒泡排序的代码,但是这个 bubbleSort 函数参数类型只能为 int64 ,也就是说我们只能传入一个类型为 int64 切片,如果我需要传入其他类型的数据,那么我们就需要重新写一个函数逻辑是相同的代码片段但是类型又不同,这就是没有泛型带来的痛苦。
package main
import "fmt"
func bubbleSort(sequence []int64) {
for i := 0; i < len(sequence)-1; i++ {
for j := 0; j < len(sequence)-1-i; j++ {
if sequence[j] > sequence[j+1] {
sequence[j], sequence[j+1] = sequence[j+1], sequence[j]
}
}
}
}
func main() {
var sequence = []int64{12, 11, 100, 99, 88, 23}
bubbleSort(sequence)
fmt.Println(sequence)
}有时候在开发的时候,为了统一使用一个函数处理,没有泛型情况下,需要对类型进行断言处理,例如在某种情况下居然写出下面这样的代码:
func bubbleSortByInterface(sequence []interface{}) {
switch sequence[0].(type) {
case int64:
var arr []int64
for _, val := range sequence {
arr = append(arr, val.(int64))
}
for i := 0; i < len(arr)-1; i++ {
for j := 0; j < len(arr)-1-i; j++ {
if arr[j] > arr[j+1] {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
fmt.Println(arr)
case float64:
var arr []float64
for _, val := range sequence {
arr = append(arr, val.(float64))
}
for i := 0; i < len(arr)-1; i++ {
for j := 0; j < len(arr)-1-i; j++ {
if arr[j] > arr[j+1] {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
fmt.Println(arr)
default:
panic("type not support!!!")
}
}然后就可以使用 interface 一把梭了:
func main() {
var sequence = []interface{}{12.12, 1.1, 99.4, 99.2, 88.8, 2.3}
bubbleSortByInterface(sequence)
// [1.1 2.3 12.12 88.8 99.2 99.4]
}但是这种一不注意就出现各种 Bug 并且代码量上去就很难阅读代码。
泛型版本
接下来就是 Go Generic 的使用介绍了, Go 支持泛型函数和泛型类型,首先我们看一下泛型函数,下面是一个标准的泛型函数标准模板:
// GenericFunc 一个标准的泛型函数模板
func GenericFunc[T any](args T) {
// logic code
}函数签名里面多了 [T any] 部分,这就是 Go 泛型的参数列表,其中 T 就是参数, any 为参数的约束。
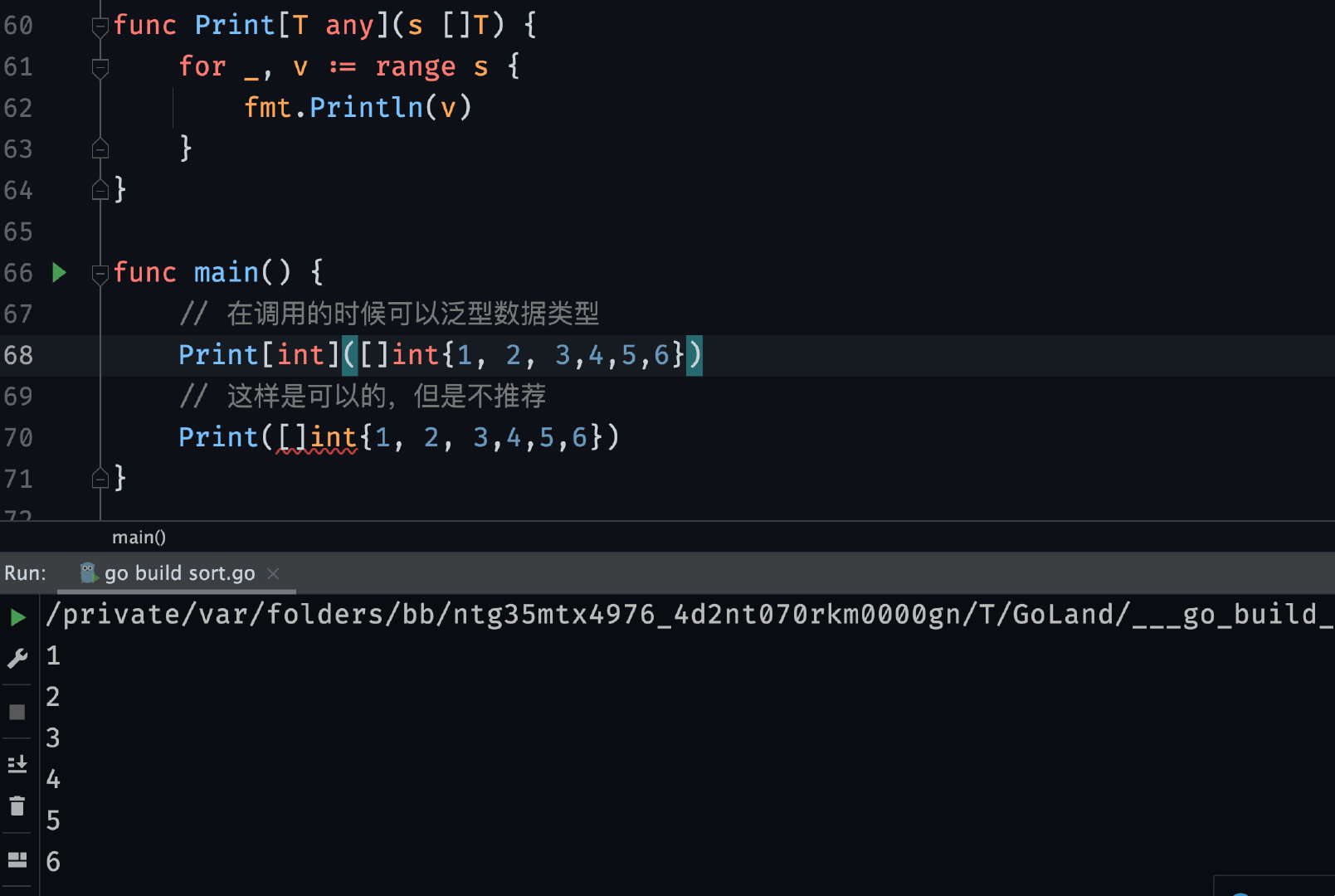
跑起来这个泛型函数,可以正常运行,但是别急,我们写一个泛型加法函数试试:

这是为什么呢?可以看到提示说:Invalid operation: a + b (the operator + is not defined on []T),这是因为我们的泛型声明 T 的类型约束在下面的逻辑代码里面进行数值运算符操作,如果大家写过Java里面的泛型都知道如果做数值比较操作,那我们的泛型类型参数还要写成 <T extends Comparable> 才能正常工作,这就是对不能进行数值运算符操作的类型进行规避操作,同理 Go 里面也是一样的。
为此 Go 语言在泛型中引入一个叫类型集合概念,下面我们改造一下代码:
// 约束参数类型只能为数值类型
func add[T int64 | float64](a, b T) T {
return a + b
}
func main() {
// 1 + 2 = 3
fmt.Println("1 + 2 =",add[int64](1, 2))
// 6.1 + 0.5 = 6.6
fmt.Println("6.1 + 0.5 =",add[float64](6.1, 0.5))
}可以看到上面可以正常运行得到正确的结果,但是有一个问题如果我们是通过内置的数据取一个类型别名怎么办?也就是以前我通过 type xx int8 这样的代码,泛型该如何限制呢?官方泛型里面映入一个 ~ 内置符号,这个符号会限制泛型参数底层是基于某种类型实现的变体或者别名,例如下面我这段代码:
type MyInt int8
// 注意看~int8
func add[T int64 | float64 | ~int8](a, b T) T {
return a + b
}
func main() {
// 限制底层数据类型
fmt.Println("MyInt 1 + 2 = ",add[MyInt](1,2))
}好了,通过上面一通操作,就知道了 Go 泛型怎么玩了,下面我把刚刚最开始那个排序算法通过泛型改写一下如下:
func bubbleSortByGeneric[T int64 | float64](sequence []T) {
for i := 0; i < len(sequence)-1; i++ {
for j := 0; j < len(sequence)-1-i; j++ {
if sequence[j] > sequence[j+1] {
sequence[j], sequence[j+1] = sequence[j+1], sequence[j]
}
}
}
}其实这个排序算法已经改写成了泛型版本,并且约束了参数的数据类型也可以认为类型的行为特征约束:
func main() {
var sequence1 = []int64{100, 23, 14, 66, 78, 12, 8}
bubbleSortByGeneric(sequence1)
fmt.Println(sequence1)
var sequence2 = []float64{120.13, 2.3, 112.3, 66.5, 78.12, 1.2, 8}
bubbleSortByGeneric(sequence2)
fmt.Println(sequence2)
}结果为下图:
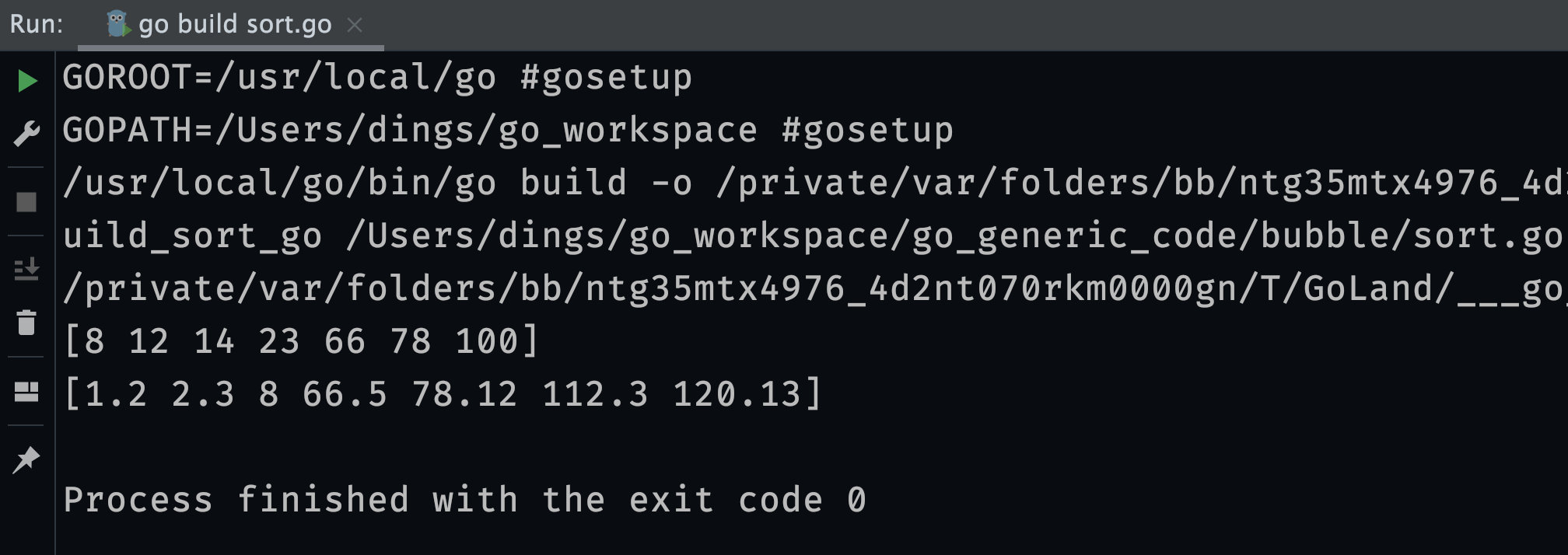
上面编写的泛型示例都是基于泛型函数进行的,但是我们有时候编程需要定义一些复合数据类型的数据结构,例如一个 Stack 结构就是内部的 Value 值类型不一样,如下的代码:
type Element interface {
int64 | float64 | string
}
type Stack[V Element] struct {
size int
value []V
}上面的代码我们就通过泛型编程定义一个 Value 类型只能为 Element 类型集合的 Stack 结构, Stac [V Element] 的中括号里面的就是泛型约束条件。
接着给 Stack 添加行为方法,方法签名上的 s *Stack[V] 就代表是一个泛型的 Stack 结构。
func (s *Stack[V]) Push(v V) {
s.value = append(s.value, v)
s.size++
}
func (s *Stack[V]) Pop() V {
e := s.value[s.size-1]
if s.size != 0 {
s.value = s.value[:s.size-1]
s.size--
}
return e
}使用就和函数泛型差不多,在中括号里面指定泛型类型:
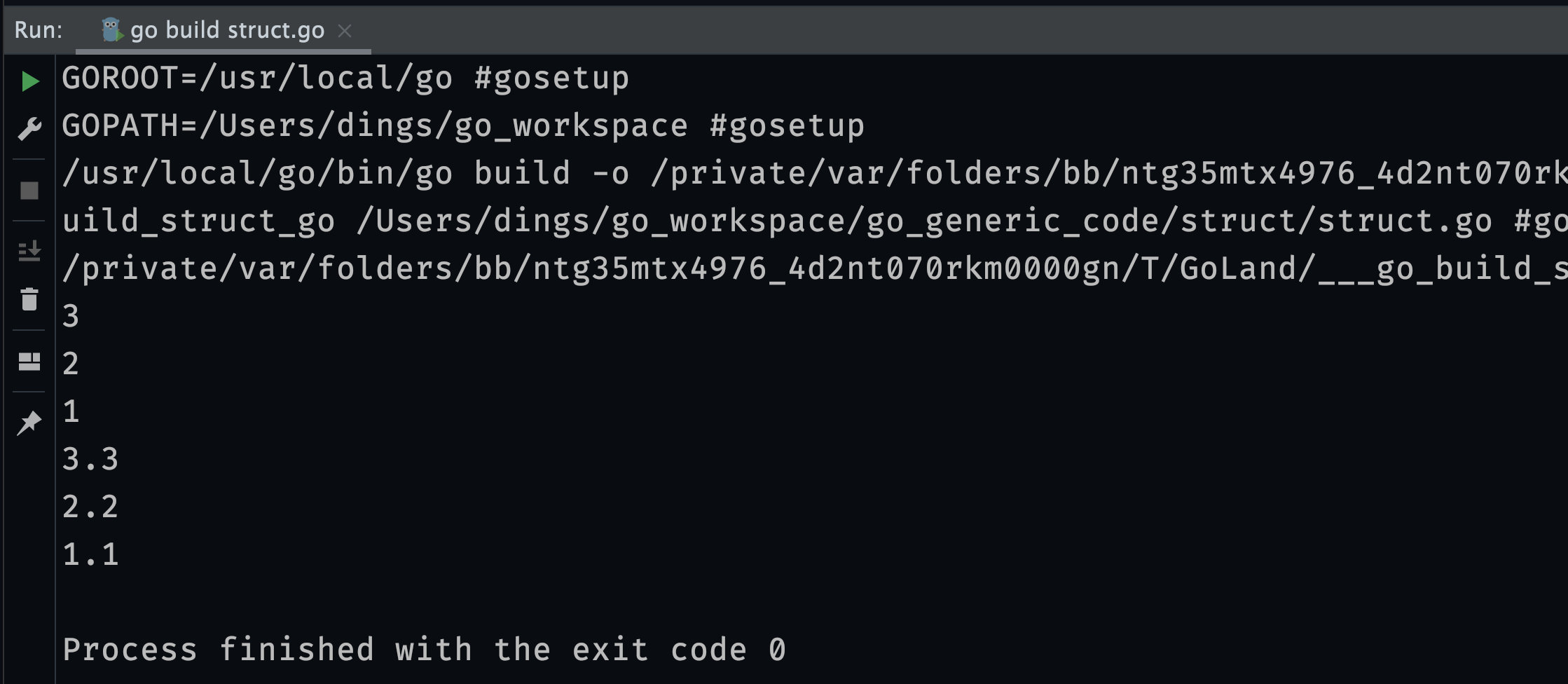
func main() {
// INT STACK
strS := Stack[int64]{}
strS.Push(1)
strS.Push(2)
strS.Push(3)
fmt.Println(strS.Pop())
fmt.Println(strS.Pop())
fmt.Println(strS.Pop())
// FLOAT STACK
floatS := Stack[float64]{}
floatS.Push(1.1)
floatS.Push(2.2)
floatS.Push(3.3)
fmt.Println(floatS.Pop())
fmt.Println(floatS.Pop())
fmt.Println(floatS.Pop())
}
另外一种就是特殊比较约束,也就是上面我所的 Java 里面的 <T extends Comparable> ,比如有时候我们需要限制某个参数是否可以比较或者支持某特征某个行为,例如可比较 comparable 关键字:
func SumNumbers[K comparable, V Number](m map[K]V) V {
var s V
for _, v := range m {
s += v
}
return s
}
func whoisMin[T Number](a, b T) T {
if a < b {
return a
}
return b
}
func main() {
// Initialize a map for the integer values
ints := map[string]int64{
"first": 34,
"second": 12,
}
// Initialize a map for the float values
floats := map[int8]float64{
-128: 35.98,
127: 26.99,
}
fmt.Printf("Generic Sums with Constraint: %v and %v\n",
SumNumbers(ints),
SumNumbers(floats))
fmt.Println(whoisMin[int64](100, 1000))
}上面的 comparable 关键字就可以限制 Map 的 Key 的类型是否为可比较的,说到这里我估计过不了多久某些卷王肯定又要跑去分析一下 comparable 底层实现了,我其实挺反感这样的卷王的,我不知道某些没事做的就跑去分析一下底层代码实现卷王有什么优越感???除了面试八股一下,难到你要去实现GO编译器吗?
不用分析了,我顺带说一下,其实 comparable 底层实现也就是基于一个 interface 的,只是里面有一个行为方法而已,Go 内置的可比较数据类型在更新之后会默认实现 comparable ,这个如果大家使用其他编程语言的泛型,想一想也就知道怎么实现了,当前一些开发集成环境还没有更好支持,可能格式化代码存在一些问题,不过可以忽略,泛型程序写起来还是挺流畅的,其实我感觉泛型参数指定的时候使用 <T> 比较好一点,用 [T] 这种在某种情况下给人一种从 Map 里面运行函数调用一样,不过这个我猜测可能和底层实现有点关系,把生成的通用代码放到 Map 里面,而泛型约束就是 Map 的键,好了本篇关于 Go 泛型文章就写到这里了。

