前面的文章介绍了Inter-Process communication 来帮助两个进程之间数据通讯,本质上还是在内存给数据做了一层行为的抽象和API封装。本篇我将会写一些对应共享内存演进出来的直接通信和间接通信的一些探讨,和一些受此影响的编程语言设计。
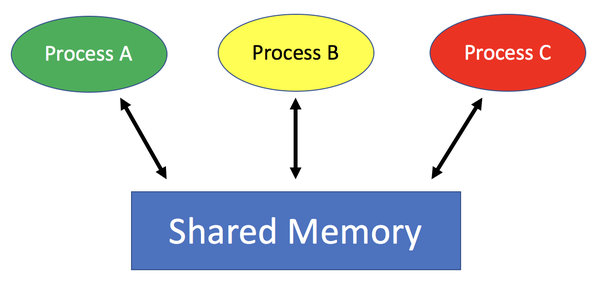
在我阅读了很多的关于Inter-Process communication 资料之后,IPC主要功能是通信,但是围绕着通信还有一些其他环境因素:通信的方式是同步还是异步,多对一通信问题,某一个进程无响应问题,权限问题,超时机制和如何管理多个通信请求?这些都是IPC设计者和实现者要解决的问题。
同步与异步
同步的方式: 首先介绍同步和异步之前得说明一些消息传递的方向几种方式,第一种是单向的,第二种是双向的,第三种根据参数来控制是单向还是双向通信。前面的文章介绍的工作原理部分是Inter-Process communication介绍的是具体实现,说的是同步方式的实现。如果进程通讯任何一方阻塞了那么另外一方也会被阻塞,必须等待对方有回应才能正常工作。
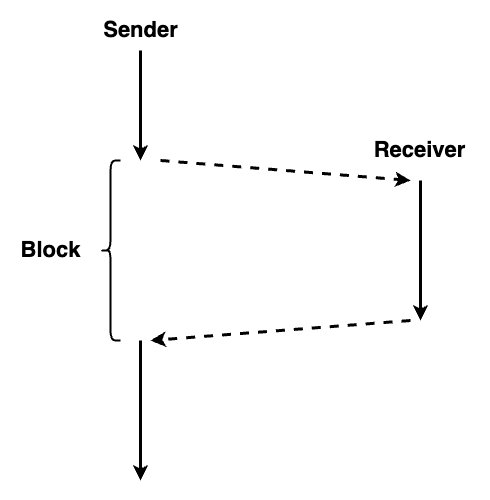
上图就为同步的方式这和IO模型的里面的同步阻塞也是一个道理,需要两个独立进程完全准备好配合好才能正常工作。在调用者发起通信时如果被调用者没有准备好也会阻塞,被调用者在处理请求时也会阻塞,直到被调用者处理完成。
同步通信的方式完全可以看成是一个系统函数调用的方式,和日常开发做的函数调用一样,如果函数内部没有返回那么其调用者也会被阻塞着,这就是同步IPC调用,如下伪代码:
package main
import (
"fmt"
"time"
)
func main() {
res := ipcCall(5)
fmt.Println(res)
}
func ipcCall(i int) int {
time.Sleep(2 * time.Second)
return i * 2
}异步的方式: 首先介绍异步之前要明白为什么要异步?异步的适用的场景是什么?同步的方式要双方配合好才能正常通信,异步相比同就省事的多了,当调用者发出请求的时候到达被调用者的时候,被调用者的处理逻辑没有准备好也没有事,请求发出即返回,逻辑是异步处理的。
异步方面的应用这里不单单是能放在OS设计的IPC上,在Node.Js上的Evnet Loop也是异步,在异步函数处理的会被注册回调函数,将整个函数调用扔给系统内核去做,内核处理完成之后将其扔到反馈队列中,Js调用栈再去取回调函数执行,下面就为Node.Js基本架构:
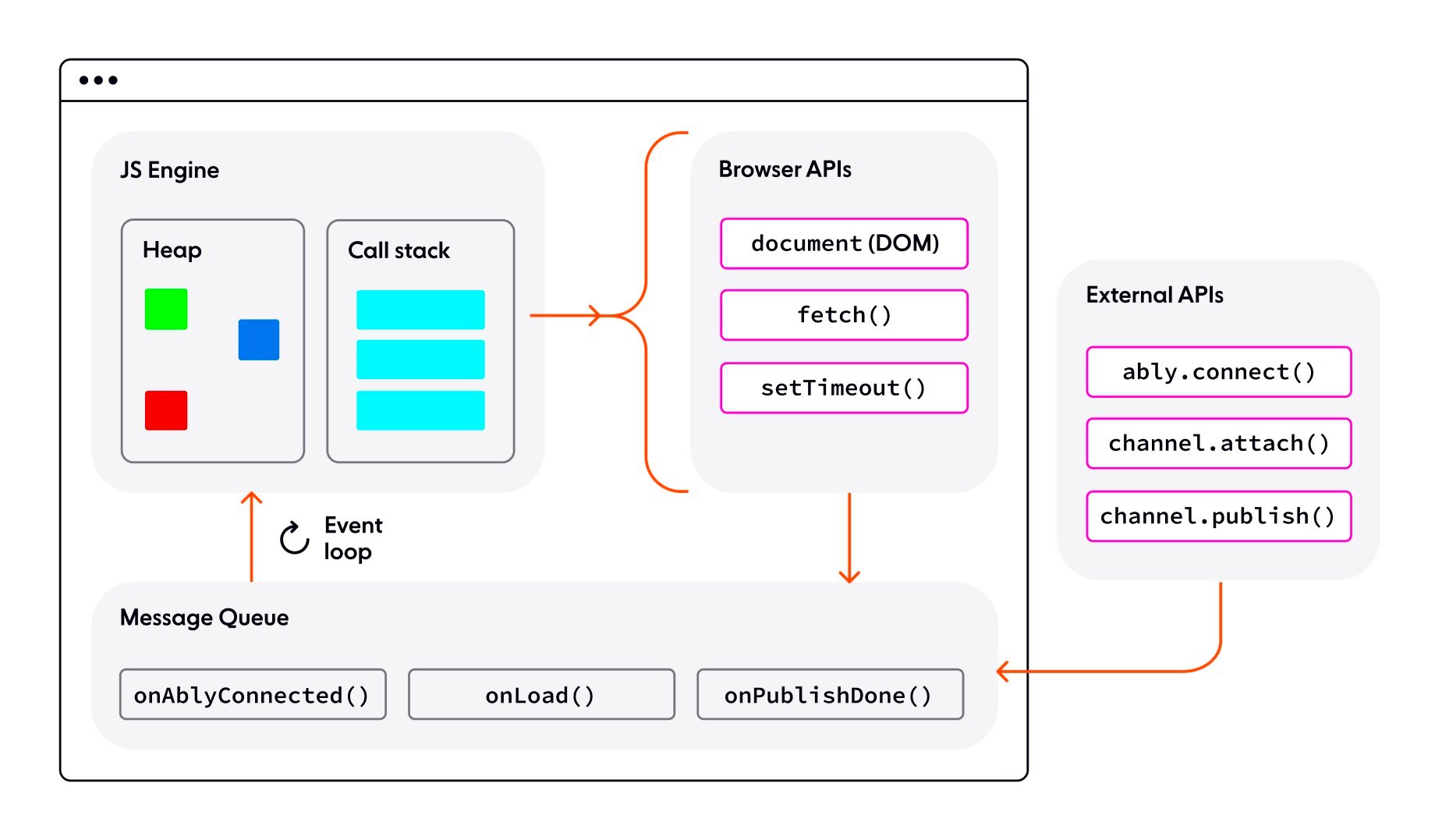
在IPC设计中如果多个调用者那么可以注册回调函数,让其调用者进行做其他的事情,也可以做多请求的处理工作。
这么看的话把通信实现就可以分为直接通信和间接通信,同步就可以认为是直接通讯的编写,而间接通讯则可以认为异步的,靠着缓冲区临时存放数据再来完成。同步IPC实现如果大量的调用者请求过来时,而被调用者没有适当的线程来处理请求时就会发生阻塞,过多的线程又会导致大量的线程浪费;而异步可以使用少量的线程完成多个调用者的请求,异步处理回调。
package main
import (
"fmt"
"sync"
)
func main() {
wg := new(sync.WaitGroup)
ch := make(chan int, 10)
// more sender
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
ch <- i
}(i)
}
wg.Wait()
close(ch)
// single receiver
for v := range ch {
fmt.Println(v)
}
}上面的代码内容就是Go语言中的多个协程间通讯使用的是channel,只要共享channel来共享数据通信,上面的代码就可以表示多个调用者对应一个被调用者的模型,channel就为缓冲区,存放临时参数数据,这也属于间接通讯。
超时控制
很多时候多个OS进程在通过IPC通讯的时候,可能出现其中一个异常退出情况,或被调用者不能及时处理请求导致请求一直未响应。看操作系统的IPC通讯设计的超时控制,其他方面也有应用例如HTTP请求超时,这些都是在超时机制应用,例如下面是一个HTTP服务端的超时控制流程:
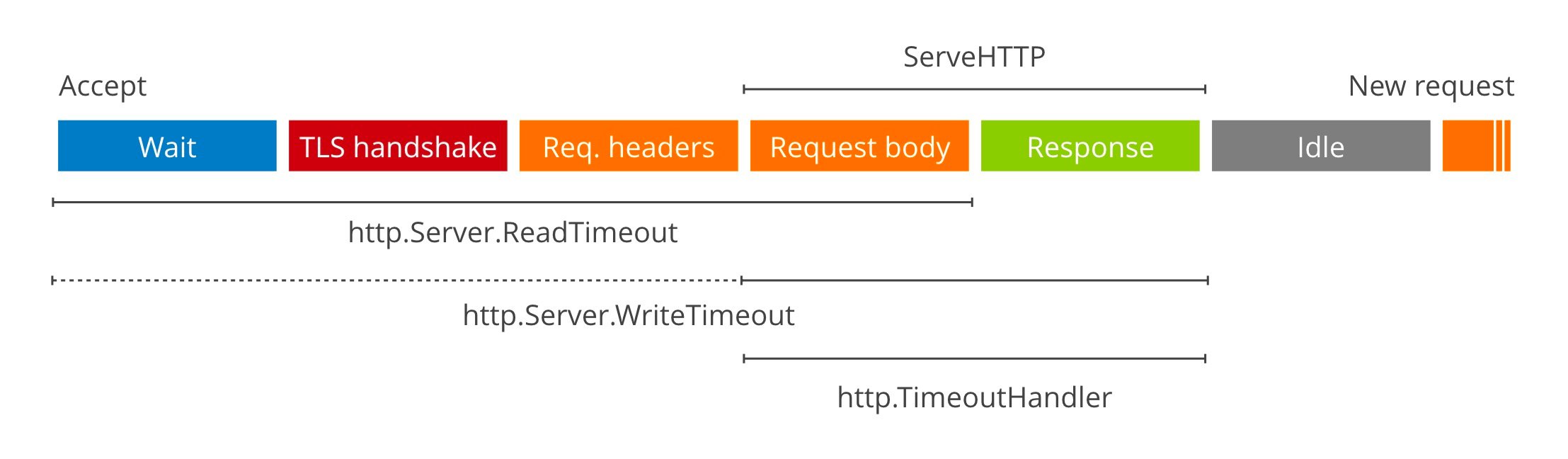
有了超时控制能让我们写的一些程序能快速失败,当我们发起一个请求的时候,如果对方不能满足正常工作状态或者本在允许的访问内响应结果,可以快速终止一个请求,避免浪费响应时间,如下图在微服务中的多个服务之间的超时控制:
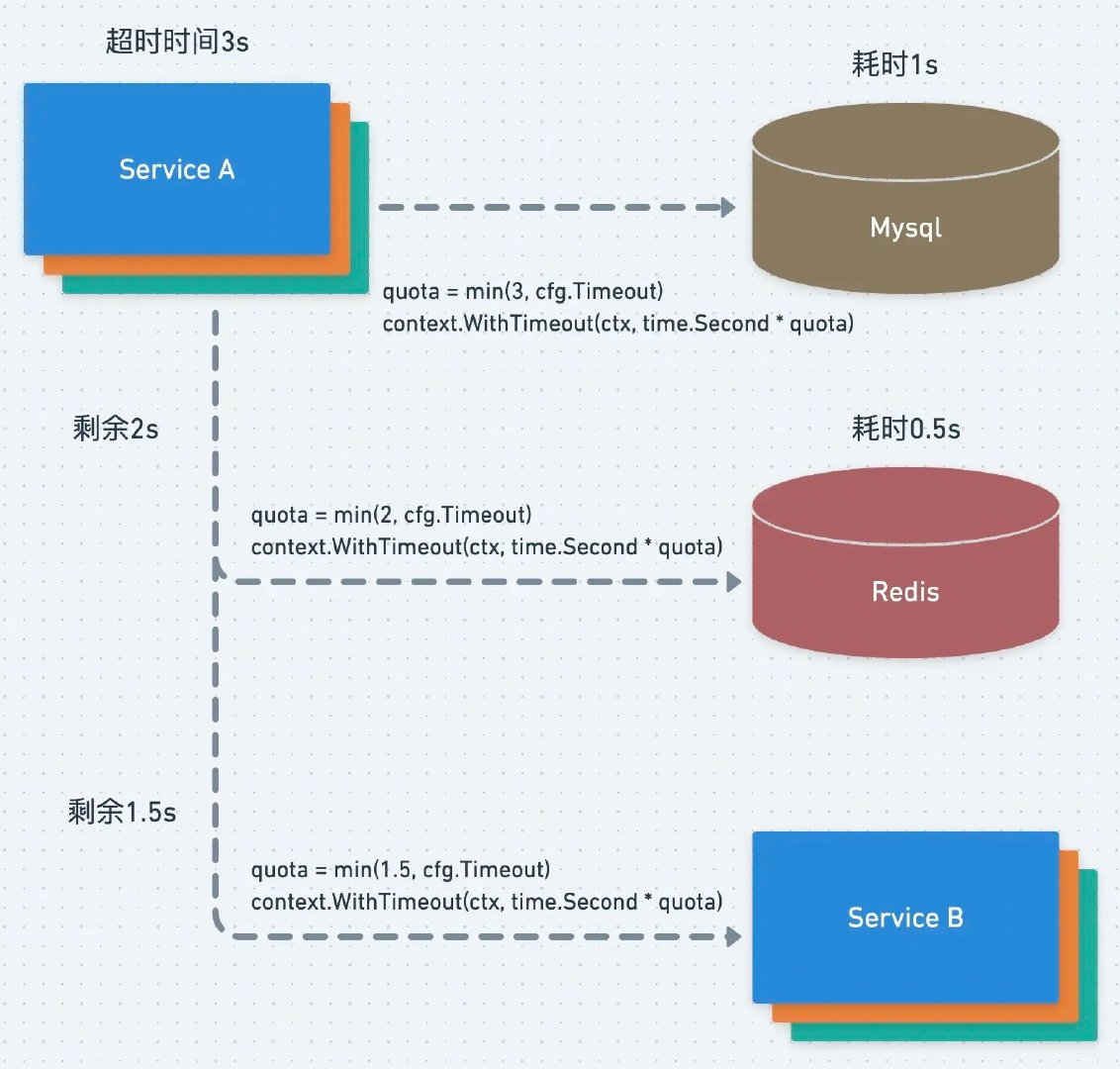
超时机制在调用者发起方,因为被调用者的逻辑可能不是由自己编写的,当被调用者收到请求恶意不处理,那么调用者就无法进行执行任务,所有超时控制是必备的,当时怎么设计一个合理的超时时间也是要根据自己的场景的,如果是需要立即返回的应用建议使用同步通讯的方式并且可以设置较短的超时时间,而如果不需要立即返回的应用可以异步处理,超时时间可以长一些。
下面的可以把channel看成一个间接通讯的缓冲区信箱📪,多个协程共享着这个channel通讯,多个独立的执行体共享着这一管道:
package main
import (
"context"
"fmt"
"runtime"
"sync"
"time"
)
var wg = sync.WaitGroup{}
const total = 10
func main() {
wg.Add(total)
now := time.Now()
for i := 0; i < total; i++ {
go func() {
defer func() {
if p := recover(); p != nil {
fmt.Println("oops, panic")
}
}()
defer wg.Done()
requestWork(context.Background(), "any")
}()
}
wg.Wait()
fmt.Println("elapsed:", time.Since(now))
time.Sleep(time.Second * 5)
fmt.Println("number of goroutines:", runtime.NumGoroutine())
}
func requestWork(ctx context.Context, job interface{}) error {
ctx, cancel := context.WithTimeout(ctx, time.Second*2)
defer cancel()
// 控制请求超时结果
done := make(chan error, 1)
// 处理请求异常
panicChan := make(chan interface{}, 1)
go func() {
defer func() {
if p := recover(); p != nil {
panicChan <- p
}
}()
done <- hardWork(job)
}()
select {
case err := <-done:
return err
case p := <-panicChan:
panic(p)
case <-ctx.Done():
// 此处错误为捕获
return ctx.Err()
}
}
func hardWork(job interface{}) error {
time.Sleep(time.Second * 4)
return nil
}例如上面代码是Go中的协程之间超时控制,使用内置的context.WithTimeout来完成超时控制功能。
权限控制
不管在什么样的类型系统里都会有安全控制这个功能,对一个面向多用户的操作系统来说,安全功能更是如此的重要,本节将介绍操作系统中安全权限检测模型,如何在多进程之间能共享数据的访问的。
相信上面这幅图片里面内容大部分都看到过,这就是类似Unix系统中的文件权限控制,那如何去定义一个安全的权限鉴权模型呢?
在Linux安全鉴权模型中被划分成了:用户组、所有者、文件是否可读写、文件是否可执行。
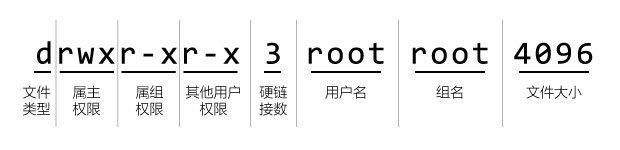
上图就为Linux中的安全权限模型,每个项都有自己独特的含义,在Linux中这些权限都是保存在权限文件中的,用户权限文件/etc/passwd,而保存组信息的文件是/etc/group,保存密码口令及其变动信息的文件是/etc/shadow,下面是一个系统用户信息文件的内容:
[Linux]$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin在Linux这些IPC通信权限被抽象成了一个名为ipc_perm的结构体,内容如下:
struct ipc_perm {
key_t __key; /* Key supplied to shmget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions + SHM_DEST and
SHM_LOCKED flags */
unsigned short __seq; /* Sequence number */
}; 通过上面字段就看出对文件描述符的权限检测还有访问模式的控制,以及用户组和用户发权限控制。
System V IPC
在Linux中宏内核操作系统通讯实现被称为System V Interprocess Communication (IPC)具体实现方式就3种和上一篇文章讨论的内容很接近,分别为:消息队列、信号量、共享内存,如下图:

管道通信在实现细节上被分为了匿名管道和命名管道,两种相同实现都是在内核中分配一快连续的空间,通过数据字节序列来通信,数据存放顺序是FIFO的方式进行组织。例如使用cat HelloWorld.java | grep "Hello"来操作多个命令时,这时就是使用的管道通讯,把上一个程序的输出放到下一个程序的输入,如下图:

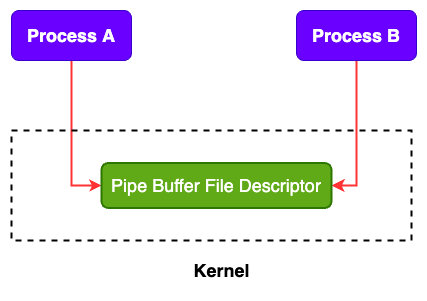
匿名管道: 匿名管道的创建方式依赖操作系统,通过系统调用创建的管道,当创建完成之后两个独立的进程会得到内核返回的文件描述符,管道是没有名称的,只能通过文件描述符进行数据读写操作,这种方式创建的管道当父亲进程fork新的进程,子进程也会共享这个文件描述符,需要注意的是父子进程之间读写端口控制,如果两个都没有关闭,会产生数据竞争问题,如下图:
命名管道: 命名管道要解决的问题就是匿名管道只能通过文件描述符来读写,而命名管道可以通过指定一个全局文件名来进行访问,在类Unix下可以使用mkfifo命令进行创建一个命名管道,例如下图:
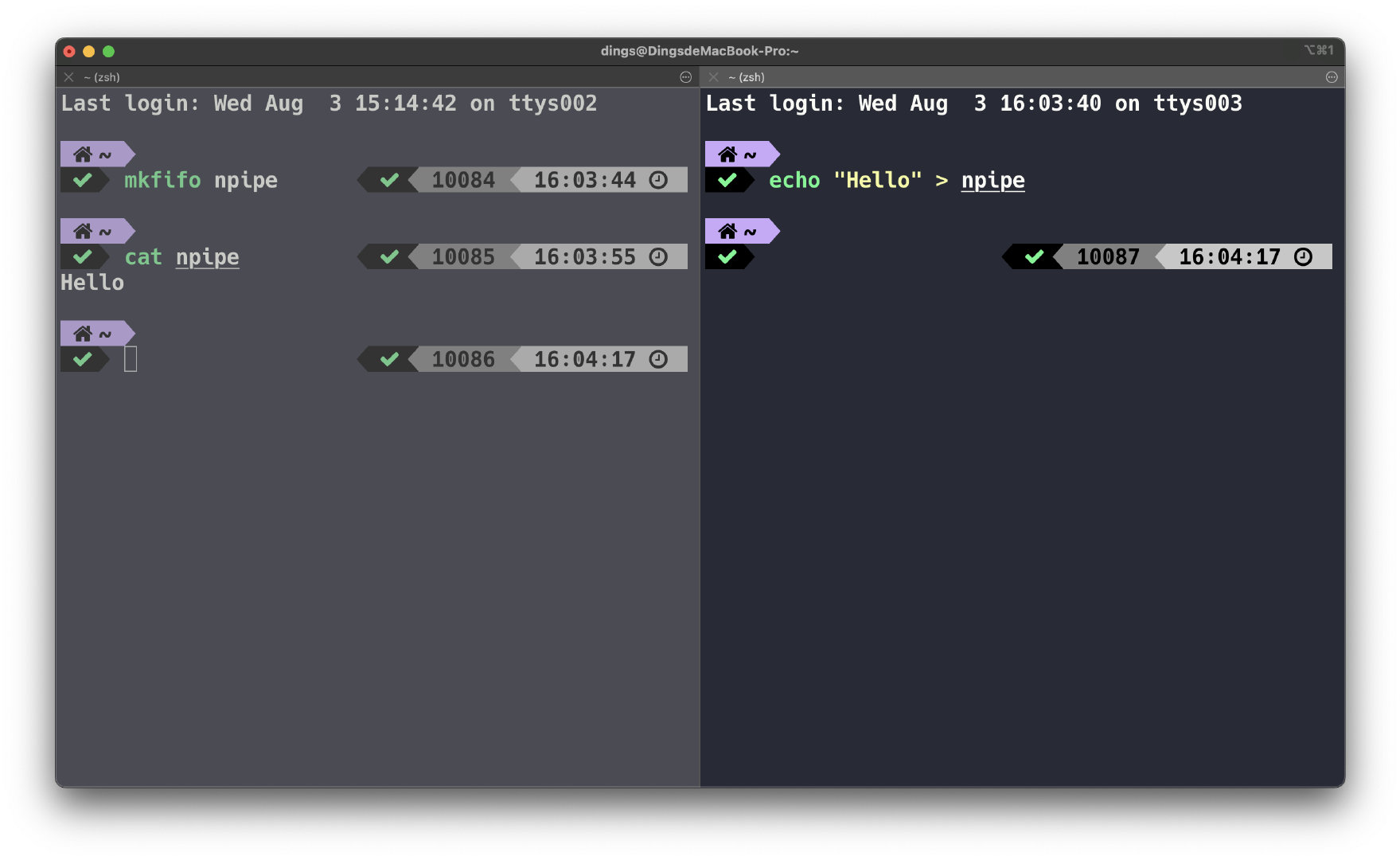
通过这种方式两个独立进程可以通过相同的管道名进行通信。
信号量: 信号量是Linux中独特创建一种独立进程间的通讯方式,信号量在实际的使用中主要用于进程间的同步,多个进程如果用通道的方式会有缓冲区还有消息队列不能及时做到同步,而型号量能够满足及时同步的场景需求,代码如下:
#include <sys/sem.h>
struct semid_ds
{
struct ipc_perm sem_perm; //指向与信号量集相对应的ipc_perm结构的指针
struct sem *sem_base; //指向这个集合中第一个信号量的指针
ushort sem_nsems; //集合中信号量的数量
time_t sem_otime; //最近一次调用semop函数的时间
time_t sem_ctime; //最近一次改变的时间
};
// semid_ds结构中的sem结构记录了单一信号量的一些信息
struct sem
{
ushort semval; //信号量的值
pid_t sempid; //最近一次执行操作的进程的进程号
ushort semncnt; //等待信号值增长,即等待可利用资源出现的进程数
ushort semzcnt; //等待信号值减少,即等待全部资源可被独占的进程数
};信号量大部分应用场景就是多个进程想去访问一些公共资源资源临界区时,一种用于临界资源的互斥访问,临界资源在同一时刻只允许一个进程使用,此时的信号量是一个二元信号量,它只控制一个资源;例如下图,如果信号量是正数,就可以使用这个资源。进程将信号量的值减一,表示当前进程占用了一份资源;如果信号量是0,那么进程进入睡眠状态,直到信号量的值重新大于0时被唤醒,以此类推。
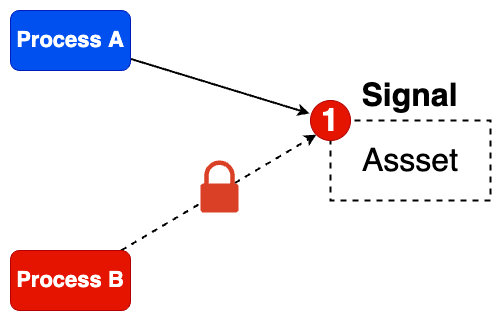
信号量的一个简单的设计是限制其计数器的值范围只能是0至1之间变化的,如果当前计数器为1说明资源可用,而为0说明资源不可用,其值不能大于1,这个对应的操作是执行V操作是增加1,而执行P操作时会减1,并且操作为原子操作,这就是基本核心功能型号量通信的设计。
消息队列: 消息队列的方式会帮两个独立进程之间需要传递的数据打包抽象成一个消息队列,而消息队列的实现是一个链表,由于是链表的方式可以支持多个发送者和消费者,如下图:
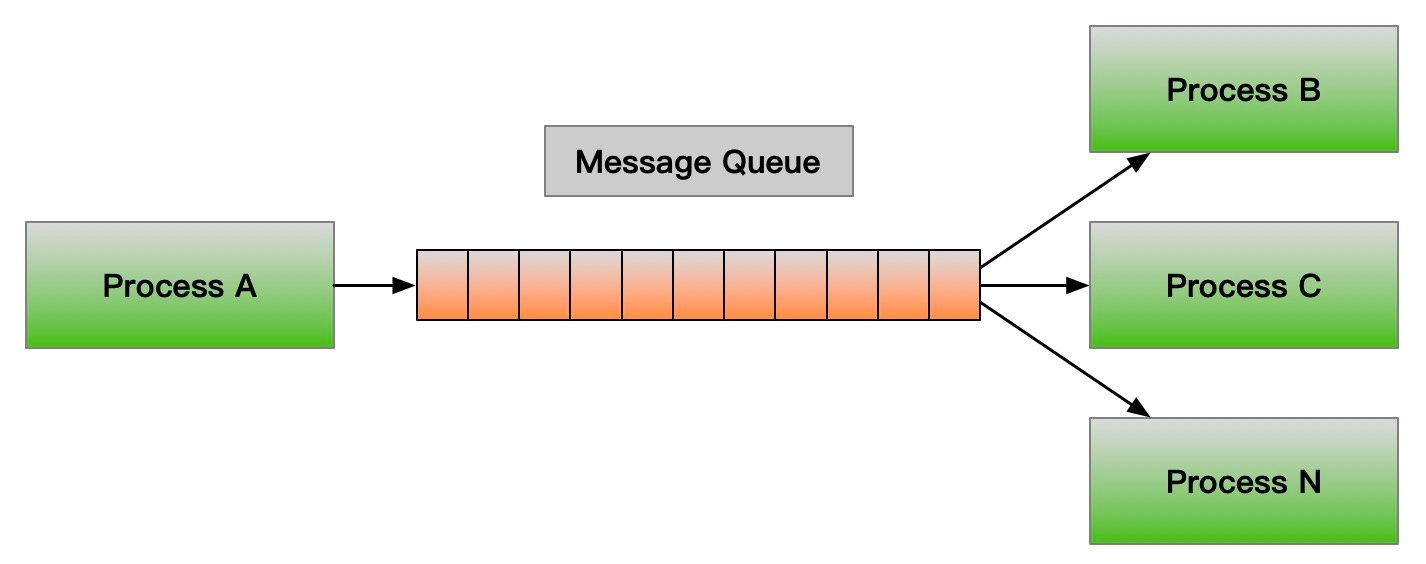
一个进程写入,一个或者多个进程进行读取,一个进程写入多种不同的数据包,多个进程按照消息类型进行读取。内存的中实现就是一个链表,但是每个数据包有自己的数据类型和数据实体还有一个指向下一个数据包的指针,消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级,消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除,消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取,如下图:
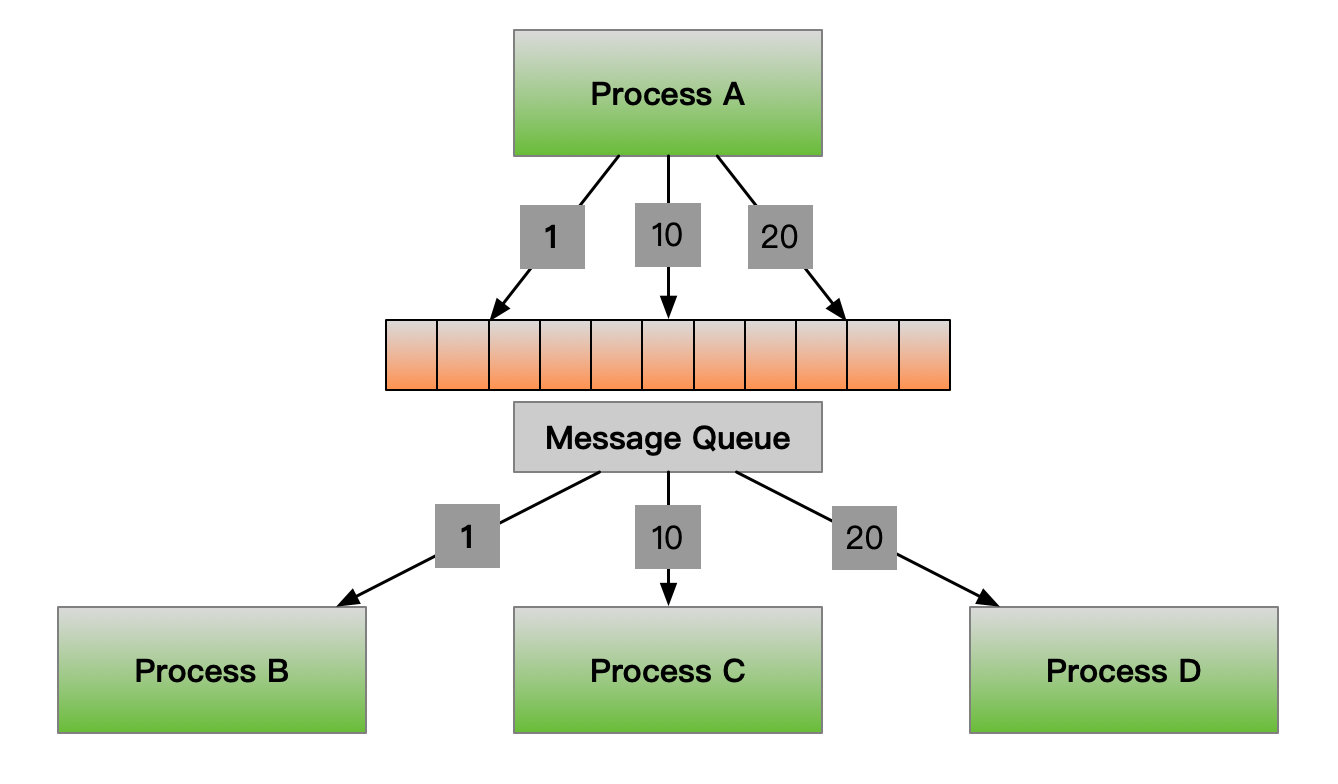
消息队列可以实现两个或者多个进程之间的通信,并且读进程可以按照消息类型进行读取,在看实例之前先了解一下使用消息队列的系统调用和流程是怎样的;内核会通过一系列的系统调用函数msgget()用于获取和创建一个队列,msgsend()向指定的消息队列中发送数据,msgrcv()从队列中获取数据,shmctl会删除消息队列,具体流程如下图:
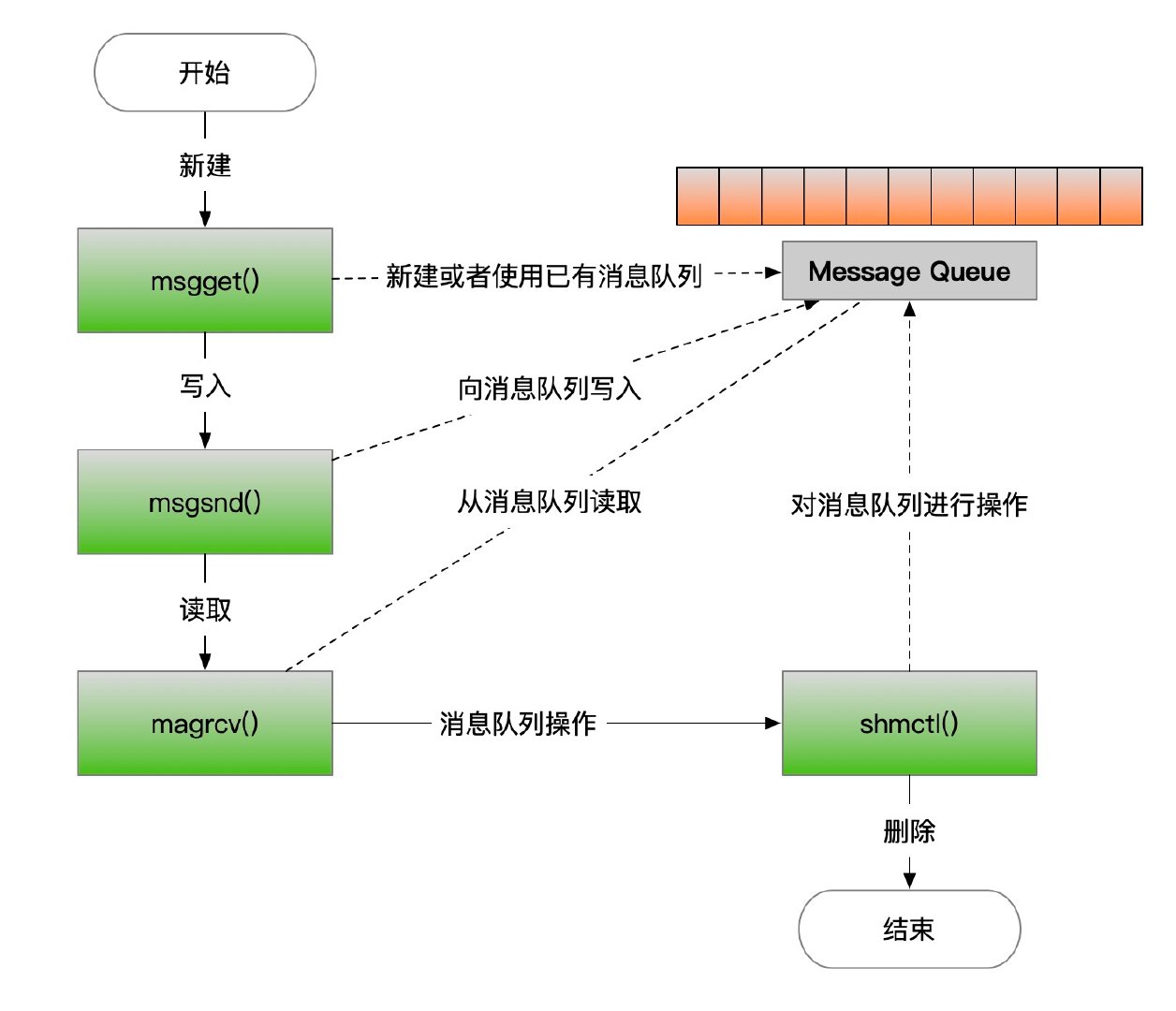
其实消息队列的实现就是双端阻塞队列,当发送者发送数据的时候如果消息队列满了就会发生阻塞,而如果接受者在接受数据的时候消息队列为空时也会发生阻塞,当然这个操作系统在系统调用有一些参数,可以来设置这些NOWAIT参数设置之后如果满就不会阻塞,而直接返回错误消息,这个设计和Go语言的channel是很像的。
小 结
进程间的通信IPC技术实现有很多种,其本质上还是在内存上做数据结构自定义抽象和实现,根据不同场景设计出来的不同方式的消息通信的方案,都是在操作系统上做的集成提供系统调用接口。本文以Linux中的System V为例介绍一些具体实现设计和每种方案针对着不同的场景,每种消息通信实现都有他独特之处,操作系统是一个非常复杂的软件特别是内核部分,学习这些可以帮助开发者能够设计出类似于Linux内核这样的优质的软件。
其他资料
- What Is Shared Memory
- Do Not Communicate By Sharing Memory
- The Ably async/await post we promised
- Non-blocking or asynchronous
- Example for sync.WaitGroup correct
- Go net/http 超时机制完全手册
- The complete guide to Go net/http timeouts
- 一文搞懂如何实现 Go 超时控制
- Linux 安全模型与权限
- System V interprocess communication mechanisms
- Linux PCI Bus Subsystem
- System V Shared Memory in Linux
- What are Pipes in Linux
- Linux进程间通信视频
- Linux IPC:Message Queue Design

