本文已参与「开源摘星计划」,欢迎正在阅读的你加入,活动链接:https://github.com/weopenprojects/WeOpen-Star
- 原文微信公众号地址: 如何为TCA集成自定义工具
本文将介绍如何为Tencent Cloud Code Analysis进行自定义开发的插件集成。首先介绍一下TCA是什么吧?是一款代码分析系统可以通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,对代码进行综合分析,验证代码是否满足规范性、安全性、可靠性、可维护性等指标的一种代码分析技术。总体来说就是可以帮助开发者在开发阶段提前分析出现项目代码的Bug或者说一些存在缺陷的地方的开发者工具。本文前面部分将介绍如何在自己的机器或在服务器环境中如何搭建起运行TCA基础运行环境,后面部分将介绍如何为TCA集成自己开发的第三方插件工具。
主仓库地址:https://github.com/Tencent/CodeAnalysis
快速开始
在部署之前需要准备的工作是你需要一台基于Linux Kernel系统的机器,至于用什么发行版本的系统这个没有什么强制的要求,哪个用着爽就用哪个;并且在系统上已经安装好了Docker,本次部署使用的Docker作为部署的方式,如果大家的机器没有安装Docker可以点击这个点击Install Docker Desktop on Linux去到官方网站下载最新版本Docker安装即可。
我本次使用的Linux环境是Ubuntu 20.04.3 LTS版本,整个系统依赖环境为下图:
如果你身处在国内可能Docker需要配置一下加速的镜像地址,这样拉取TCA镜像和依赖镜像会快一点,只需要修改vi /etc/docker/daemon.json将其内容修改为下面的地址:
{
"registry-mirrors" : [
"http://registry.docker-cn.com",
"http://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com"
],
"insecure-registries" : [
"registry.docker-cn.com",
"docker.mirrors.ustc.edu.cn"
],
"debug" : true,
"experimental" : true
}配置完成之后,可以执行命令sudo systemctl daemon-reload重新启动服务;我们就可以拉取TCA官方仓库的代码到本机上部署运行了,前提是你机器上已经安装好了Git版本管理工具,执行下面的代码即可拉取:
git clone [email protected]:tencent/CodeAnalysis.git官方在项目目录下已经提供好了供开发者使用的quick_install.sh脚本来帮助快速部署起来项目,目录结构如下:
这里执行命令脚本需要足够的权限才能执行,建议使用有高权限用户,如果你只是测试可以尝试使用Root权限,生产环境不建议你这么做!运行之前请确保你Docker已正常运行!
首次运行需要进入项目目录执行一下命令,帮助你初始化你docker环境,此命令主要作用为快速部署tca和相关依赖环境:
cd CodeAnalysis && bash ./quick_install.sh docker deploy执行命令之后Docker自动拉取相关镜像如下图所示:
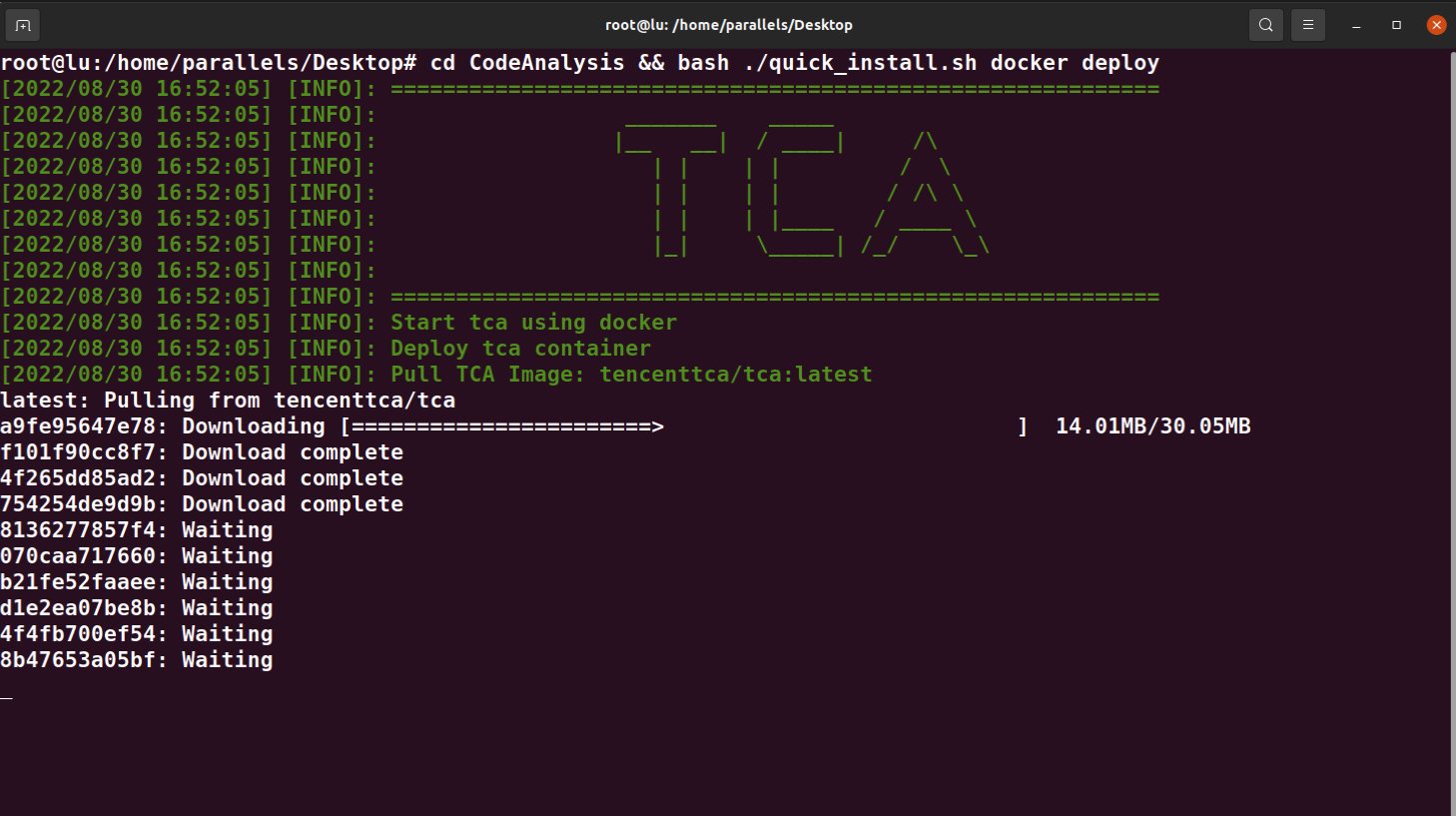
拉取镜像时间根据各自网络情况快慢,如果安装过程中出现错误可以根据程序信息排查,例如我安装过程中出现了端口被其他服务占用的情况:
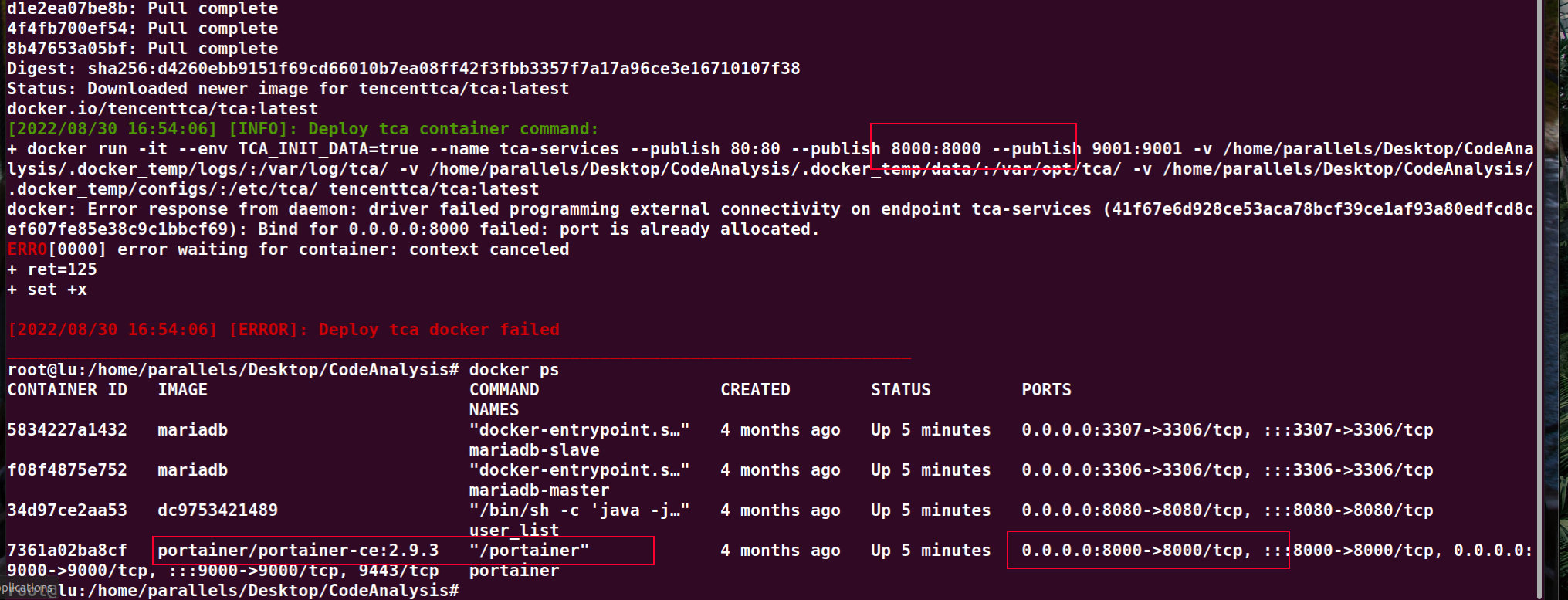
这个问题很好解决,关闭被占用端口即可,重新启动一下即可。有什么问题也可以加官方的仓库提issue提问,如果没有问题的话,脚本会输出一些配置信息日志和管理控制台访问路径如下图:
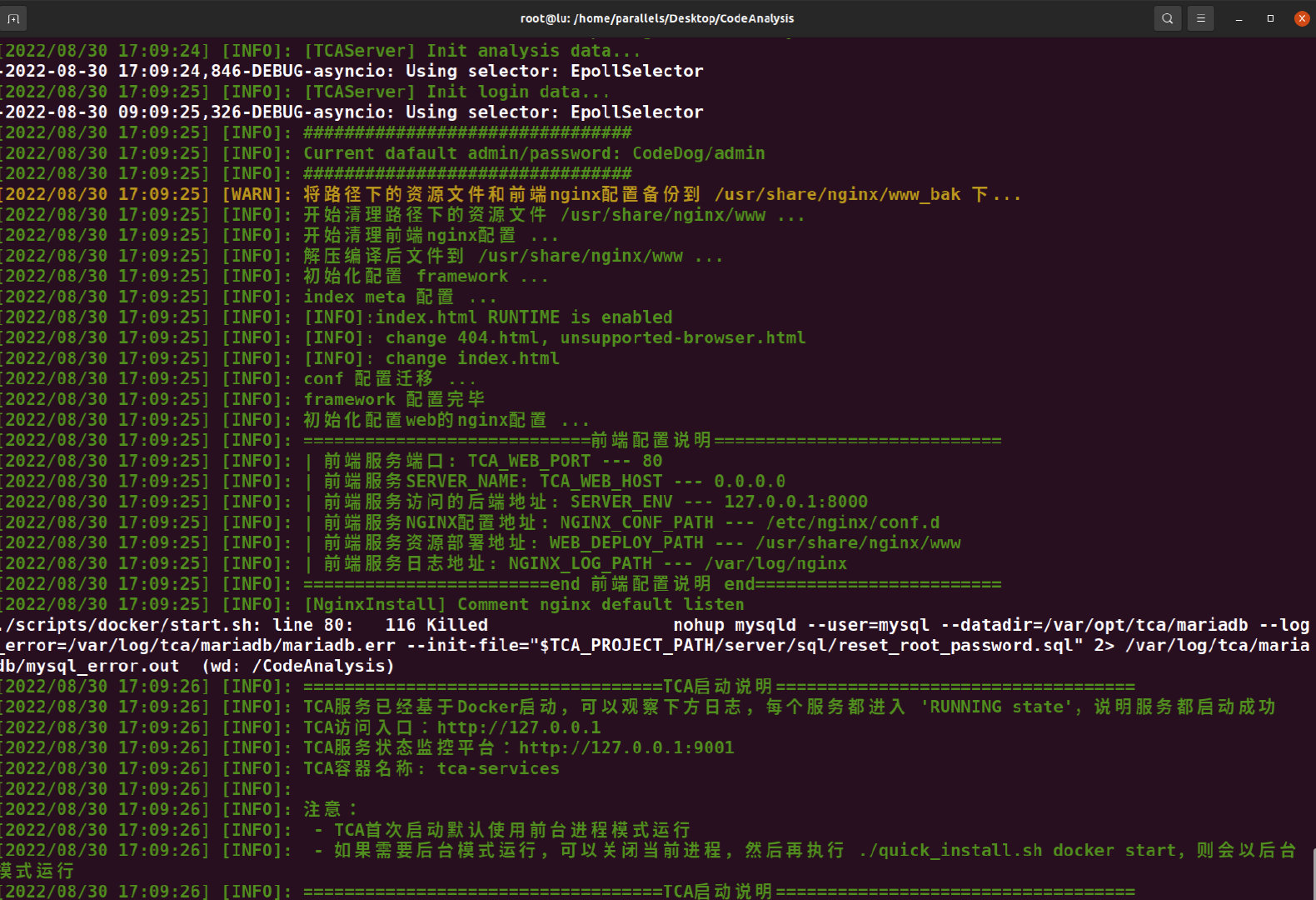
执行完以上步骤算是基础的运行环境和依赖已经全部自动化配置完成,然后需要后台运行需要开发者自己手动执行命令,如下:
bash ./quick_install.sh docker start需要注意执行此命令可能需要一分钟时间才能正常访问到管理页面,如下图:
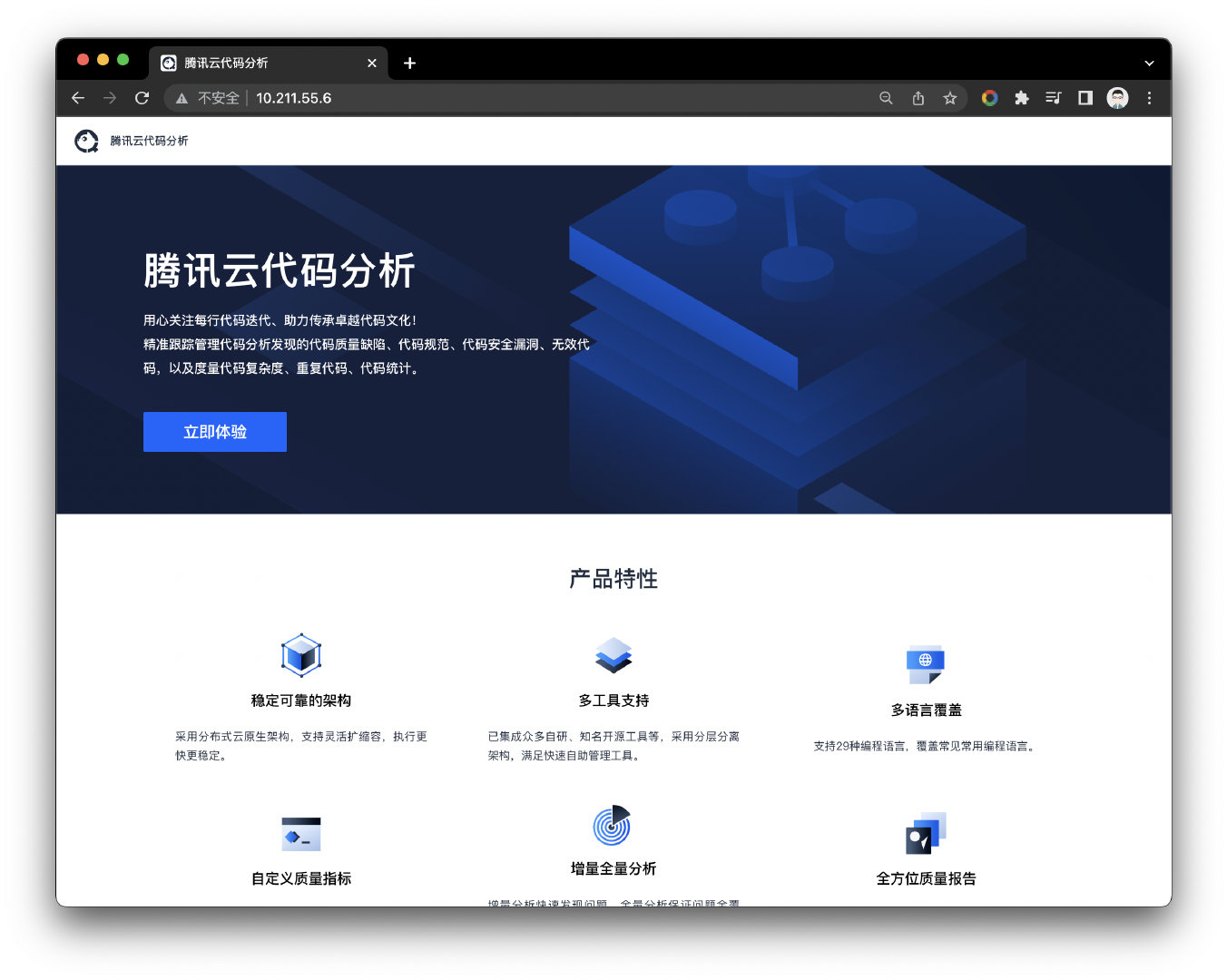
到此为止整个TCA项目已经完全部署运行起来了;点击立即体验,完成登录后即可开启您的腾讯云代码分析,默认登录账号为CodeDog密码为admin,更多细节可以查阅官方通过的文档。
集成插件
在TCA里允许第三方开发者去开发一些第三方的插件然后集成到系统里,TCA本身也提供很多官方集成的插件,也提供一些API接口让第三方去对接自定义需求的插件。这样的设计就提供更好的系统扩充性,这和VSCODE编辑器架构很接近,编辑器本身只提供核心的引擎功能,而其他功能可以通过应用插件商店获取;TCA已经拥有很多的插件工具了,如下图:
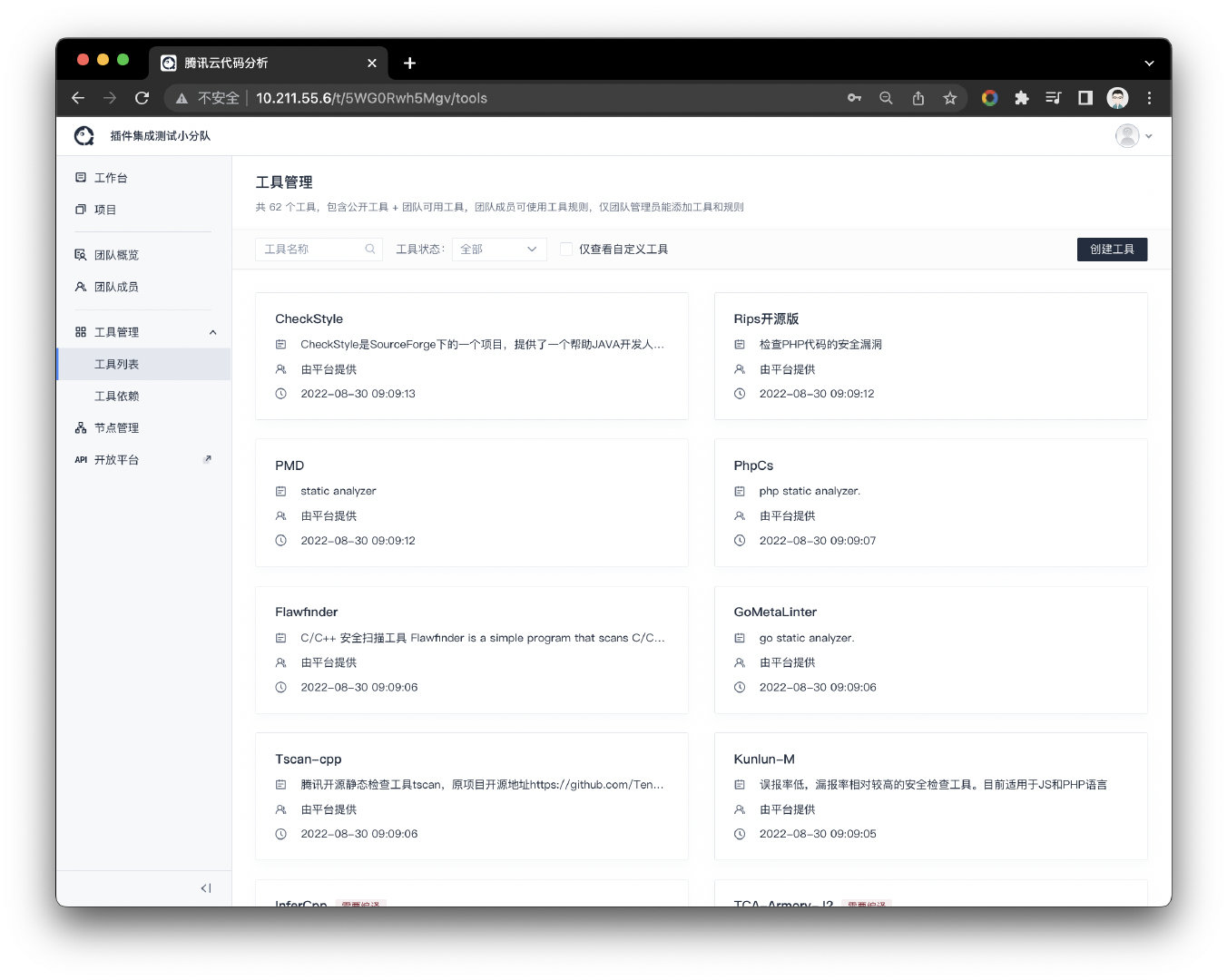
开发者可以基于现在世面上已经存在的Linter工具来做集成,对于任何语言的查找潜在BUG的过程,都可以称为Lint,Lint这个过程通常是用过对代码的静态分析来完成的。
自定义工具一些使用的场景:自定义规则无法满足团队业务复杂需求,需要更多的代码逻辑来匹配目标代码的情况。通常需要团队业务方自行实现对应代码分析工具。
要做自己的自定义的工具首先要编写符合自己的自定义代码,实现扫描逻辑,然后将其编译成可执行二进制程序是最好,也可以是源代码的方式如果是源代码的方式集成起来很麻烦因为要解决编译问题和运行环境问题。
在编写自动的自定义工具之前,可以在远程代码托管平台创建一个空仓库来放代码,后面会使用到这些,如下图:
仓库建立好之后,自定义工具逻辑要根据自己的需求去实现我这里不做过多的介绍,现在主要关注如何把自定义的工具集成到TCA主程序里面去。
当然也可以直接使用模板仓库来开发,相关issue地址:https://github.com/Tencent/CodeAnalysis/issues/586
需要注意的是按照官方插件集成规则要求要在下面目录中创建几个必备的文件,在根目录下添加一文件名为tool.json文件,声明工具的检查和扫描命令,内容模板如下:
{
"check_cmd": "python src/main.py check",
"run_cmd": "python src/main.py scan"
}你可以直接运行我编写好的这个命令快速将其写入到文件中:
echo '{
"check_cmd": "python src/main.py check",
"run_cmd": "python src/main.py scan"
}' >> tool.json两个参数说明我已经整理好表格:
| 参数名称 | 参数说明 |
|---|---|
| check_cmd | 自定义工具前置运行条件检测,例如检测系统版本环境 |
| run_cmd | 自定义逻辑程序就在这里被执行,填写要执行程序路径和参数 |
需要注意的是check_cmd将判断结果输出到check_result.json文件中,文件内容为{"usable": true}或{"usable": false}。
这里需要注意的是run_cmd的输出结构必须是官方规定的result.json的文件格式,格式内容如下:
[
{
"path": "文件绝对路径",
"line": "行号,int类型",
"column": "列号, int类型,如果工具没有输出列号信息,可以用0代替",
"msg": "提示信息",
"rule": "规则名称,可以根据需要输出不同的规则名",
"refs": [
{
"line": "回溯行号",
"msg": "提示信息",
"tag": "用一个词简要标记该行信息,比如uninit_member,member_decl等,如果没有也可以都写成一样的",
"path": "回溯行所在文件绝对路径"
}
]
}
]如果是自定义开发的工具输出结构必须为此json对应的结构体,例如下面是为我所编写的对应的语言Go语言对应的结构体:
package scan
import "encoding/json"
type Result []ResultElement
func UnmarshalResult(data []byte) (Result, error) {
var r Result
err := json.Unmarshal(data, &r)
return r, err
}
func (r *Result) Marshal() ([]byte, error) {
return json.Marshal(r)
}
type ResultElement struct {
Path string `json:"path"`
Line string `json:"line"`
Column string `json:"column"`
Msg string `json:"msg"`
Rule string `json:"rule"`
Refs []Ref `json:"refs"`
}
type Ref struct {
Line string `json:"line"`
Msg string `json:"msg"`
Tag string `json:"tag"`
Path string `json:"path"`
}另外如果你依赖的工具无法直接修改源代码的话,可以直接使用官方提供插件模板仓库:https://github.com/TCATools/demo_tool,直接使用内置的Python代码片段去集成。这个仓库已经被设置为模板仓库了,直接使用这个模板仓库,如果要开发插件的话直接fork模板仓库进行开发就行了,而模板仓库里面的内容就在其中。

这里我测试的环境是Linux系统的是所有我编写的自定义代码逻辑需要编译对应平台的二进制文件,才能正常执行,我这里的使用了我自己的编写makefile文件进行的Go语言原生交叉编译:
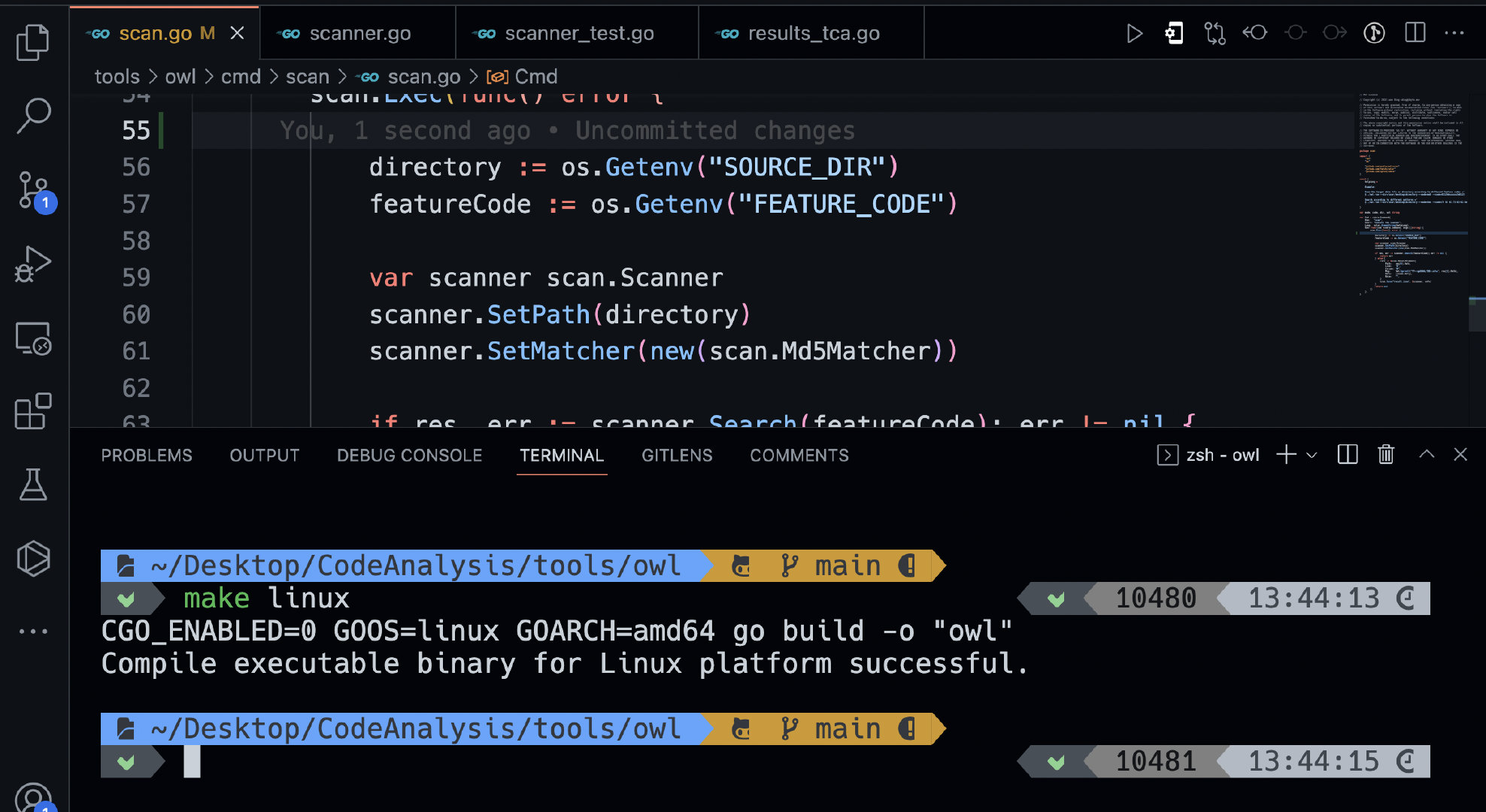
编写完成之后我们就要去配置一些环境变量,因为我这个工具是根据md5值查找对应的依赖文件的目录位置,所以可以跳过一些检查。这个比较特殊,是检查文件类型的问题,而且不一定是代码仓库下的文件,有些结果处理的阶段可以跳过,可以在工具环境变量配置里,设置一下:
FILTER_TYPE=NO_VERSION_FILTER
IGNORE_TYPE=NO_ISSUE_IGNORE
BLAME_TYPE=NO_BLAME这些字段根据各自需要可以自定义添加到环境配置中,具体需不需要要看自己的工具需求,例如下面为我编写插件核心代码逻辑,用环境变量,这些环境变量可以自定义,并且可以在程序中获取:
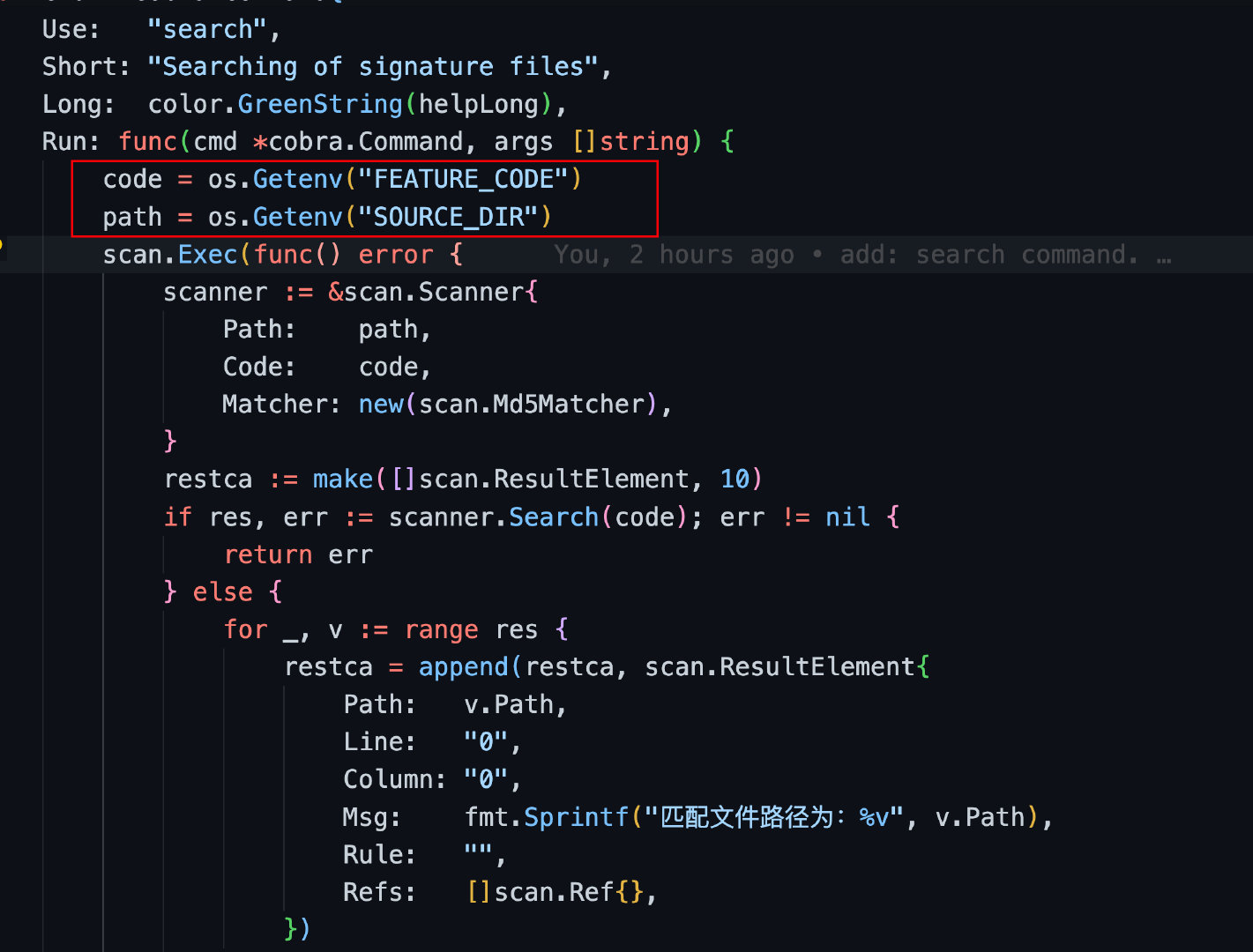
目前官方已经提供好的环境变量列表有:
SOURCE_DIR:要扫描的代码目录路径
DIFF_FILES: 值为一个json文件路径,文件内容为增量扫描的文件列表(增量扫描时可用)
SCAN_FILES: 值为一个json文件路径,文件内容为需要扫描的文件列表(增量或全量扫描均可用)
TASK_REQUEST: 值为一个json文件路径,文件内容为当前扫描任务参数当然也可以自定义,在配置插件的时候输入到插件的环境中即可。
代码编写完成之后要将其添加到TCA工具库中,需要填写自己的代码仓库地址和仓库访问的秘钥,如下:
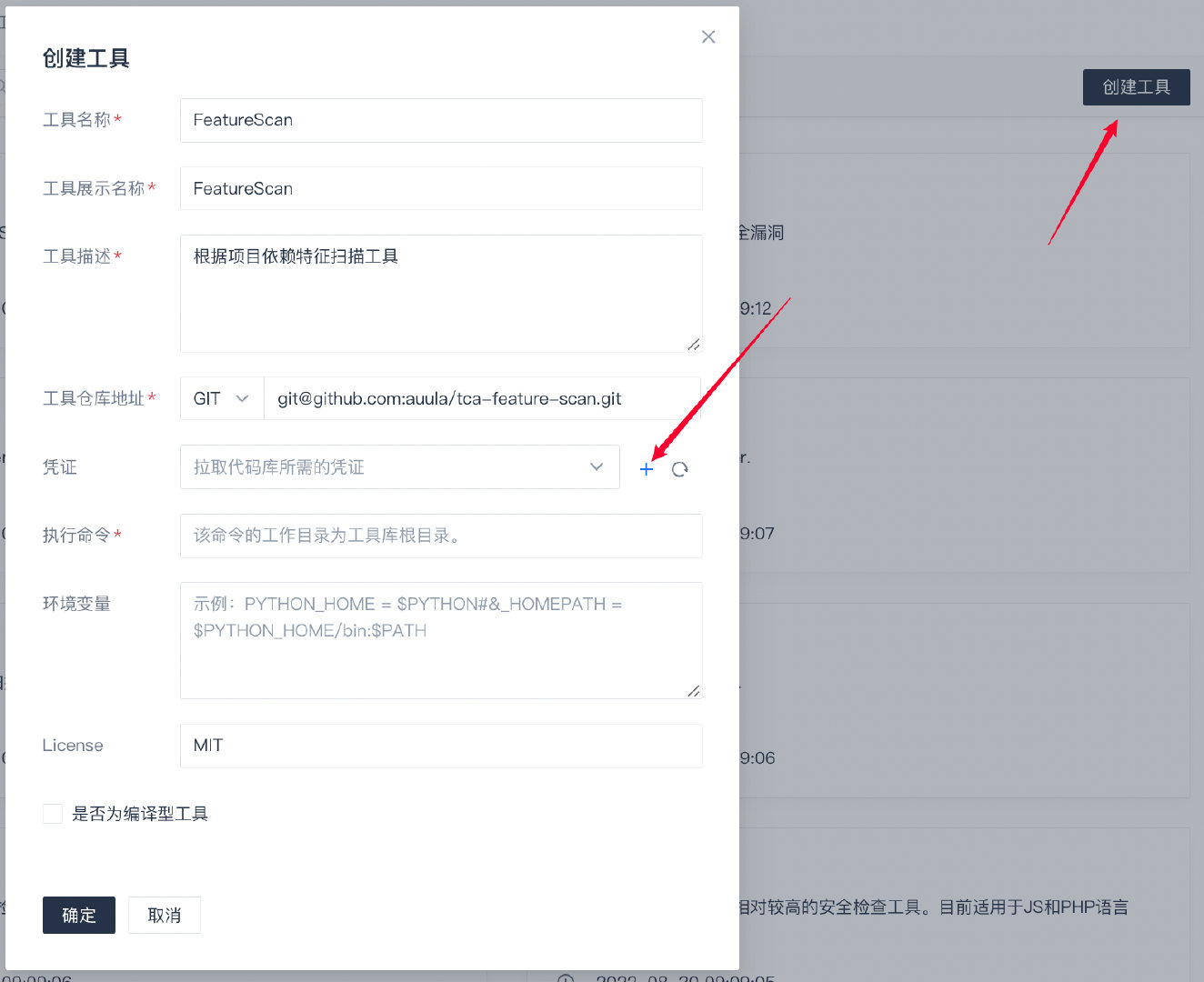
填写好相关的信息之后需要开发者自己配置访问工具代码仓库的私钥,这里也就是自己电脑上和Github公钥匹配那个私钥,一般使用下面命令即可查看如下:
cat ~/.ssh/id_rsa找到私钥之后,复制其电脑上的私钥到对话框中的,然后点击确定即可:
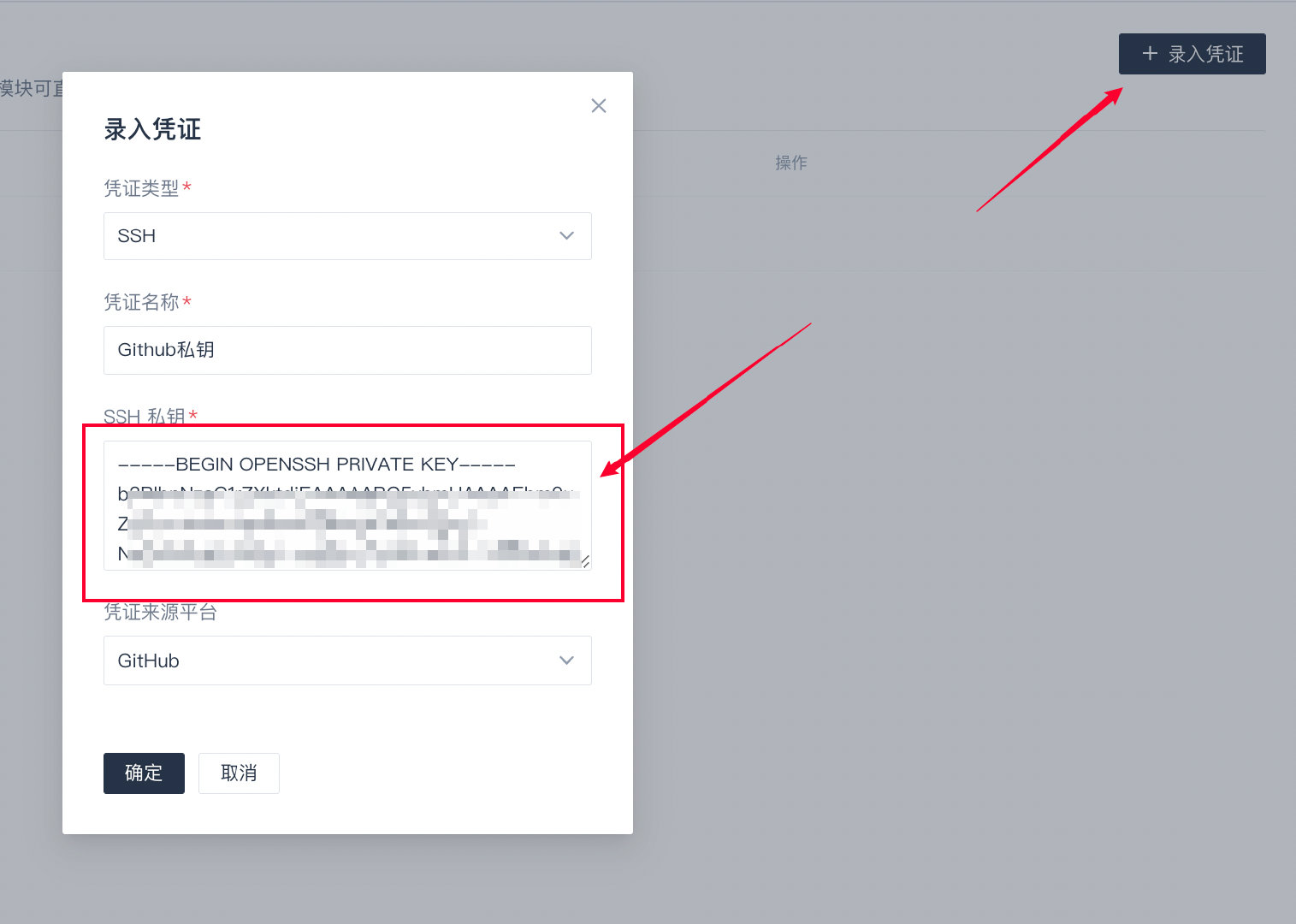
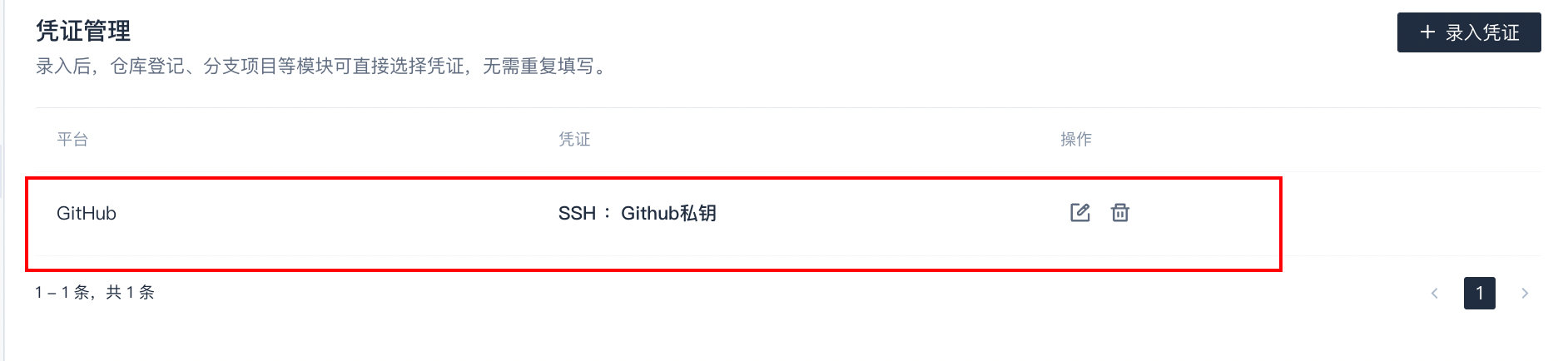
录入成功之后就可以返回插件集成页面集成插件了,也可以管理自定义的秘钥。
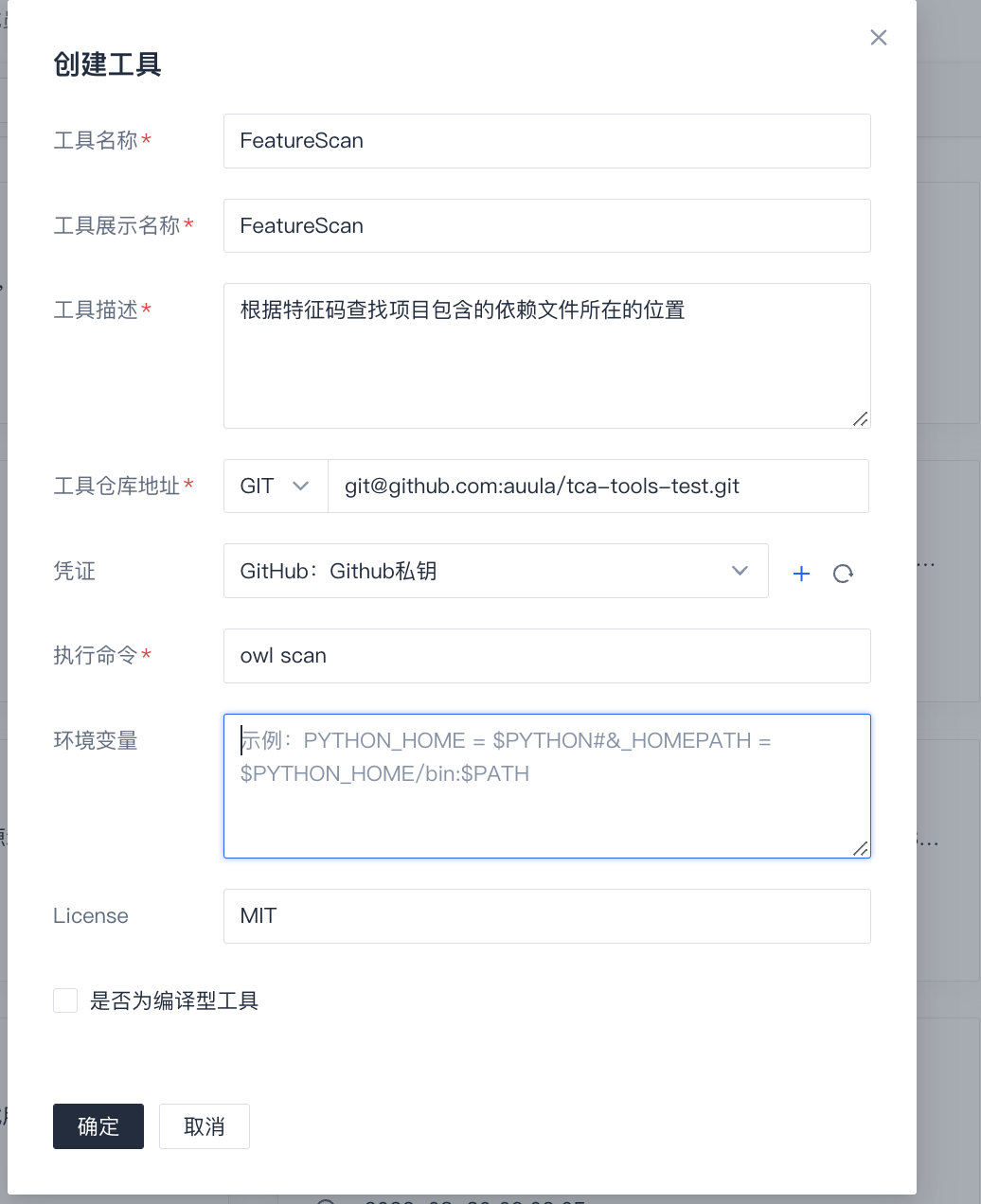
继续创建集成自定义开发的工具,如下配置自定义的工具所使用的协议,如果是依赖第三方开源工具要填写其协议,如下图:
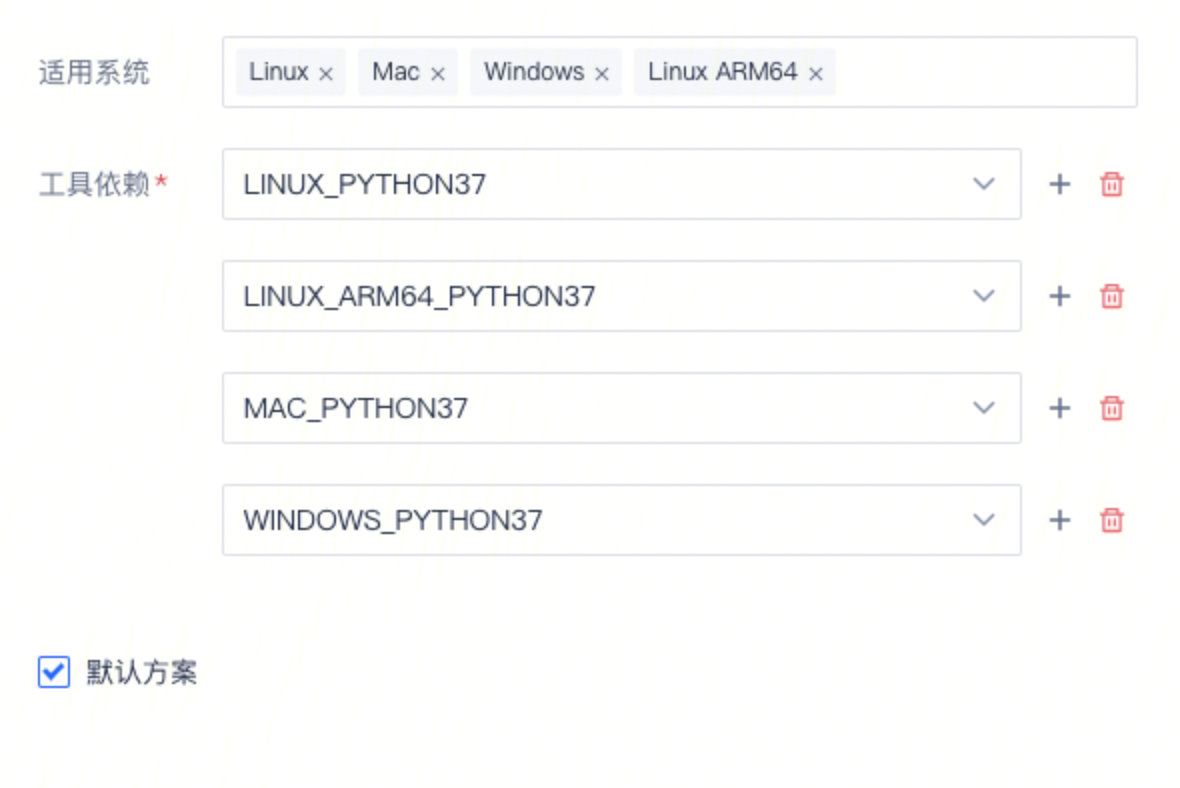
如果你的工具还需要配置工具依赖,比如要支持在linux x86_64、linux arm64、mac和windows下执行,这里就要填写相关的信息:
到处为止插件集成就可以了,更多帮助遇到问题可以去查看官方文档或者提issue。

