分布式系统对于刚刚入门作研发的程序员还是接触不多,刚刚入行的大部分程序员做的最多工作还是开发单体应用和简单业务操作,遇到最多问题估计也是本地线程并发数据安全问题,和数据状态一致性问题。而往后发展最多把单体应用部署为 HA 主从节点的方式备份架构,采用 nginx 做网络应用层的负载均衡。单体应用 bug 修复往往是万能法重启应用,让应用的状态消失,再恢复到正常状态来解决问题,但是实际上问题还是没有得到解决,除非是一些硬件故障可以跟换硬件,软件本身的问题需要开发者自己修复发布新的版本才能行。
分布式系统
- 通信协议:如何让分布式系统中的各个节点进行通信?需要确定适合该系统的通信协议,并确保节点之间的通信稳定可靠。
- 数据一致性:如何确保分布式系统中的所有节点都拥有相同的数据副本?需要选择适合该系统的数据一致性协议,如Paxos或Raft等,并在设计时确保数据的一致性。
- 负载均衡:如何在分布式系统中均衡地分配负载?需要设计适合该系统的负载均衡策略,并确保在节点故障或网络问题时系统依然可用。
- 安全性:如何保护分布式系统中的数据和节点不受攻击?需要在设计时考虑安全问题,并实现适当的安全措施,如加密和身份验证等。
- 可扩展性:如何在需要时扩展分布式系统的规模?需要设计可扩展的系统架构,以便可以添加更多的节点和处理更多的请求。
- 故障恢复:如何在节点故障或网络问题时恢复分布式系统的功能?需要设计故障恢复机制,并确保系统在出现问题时可以快速自动恢复。
- 性能优化:如何优化分布式系统的性能?需要考虑各个节点的性能特点,并尝试优化通信协议、数据一致性协议、负载均衡策略等,以获得最佳的性能表现。
扩展性
对于单体系统数据的一致性也是一个问题,例如数据库和缓存系统的数据一致性问题,当然缓存系统的数据一致性存在时间窗口的偏差是可以容忍的,但是对于分布式系统的数据一致性要考虑到问题加很多,关系型的数据库的 ACID 已经帮业务层解决了很多问题,而分布式系统特别是针对的分布式数据库,数据被分散在不同网络节点上,如何处理 ACID ?目前很多微服务架构是使用一些数据库中间件代理解决,或者说分库分表,而颠覆性的是 NewSQL 数据库例如 PingCAP 和 Amazon Aurora 分布式关系数据库来解决分布式数据一致性系统。
为提高 CAP 定律中的 P 容错机制,通常采用的方法是将数据分片复制到多个节点上,以提高数据的可靠性和容错性,同时还需要考虑 CAP 中的 A 可用机制,对节点故障进行监测和自动故障转移处理,保证系统的高可用性,NoSQL 系列例如 Redis 采用的是一致性哈希算法,Facebook Cassandra 也是一致性哈希算法,这种采用 Gossip 协议进行数据同步的,但是数据还是分区存储在当个节点上,遇到 ACID 需求无法将整个集群视为一个整体系统做强一致性数据处理,只能在单个数据节点上做 ACID 处理,并且这种分区有热点数据问题。
一致性
为了保证分区所有节点数据一致性目前大多数数据库采用的是同步复制,换句话来说往集群中一个节点写入数据其他节点马上会同步到最新的数据,但是由于分布式系统是建立于在不可靠网络之上的,如果出现分布式分区脑裂情况,导致多个分区不能通常通信,此时数据版本该从何处写入,从何处复制到集群中剩下的可以节点中?目前大多数 NewSQL 采用两种分布式算法解决的,Raft 和 Paxos 算法。
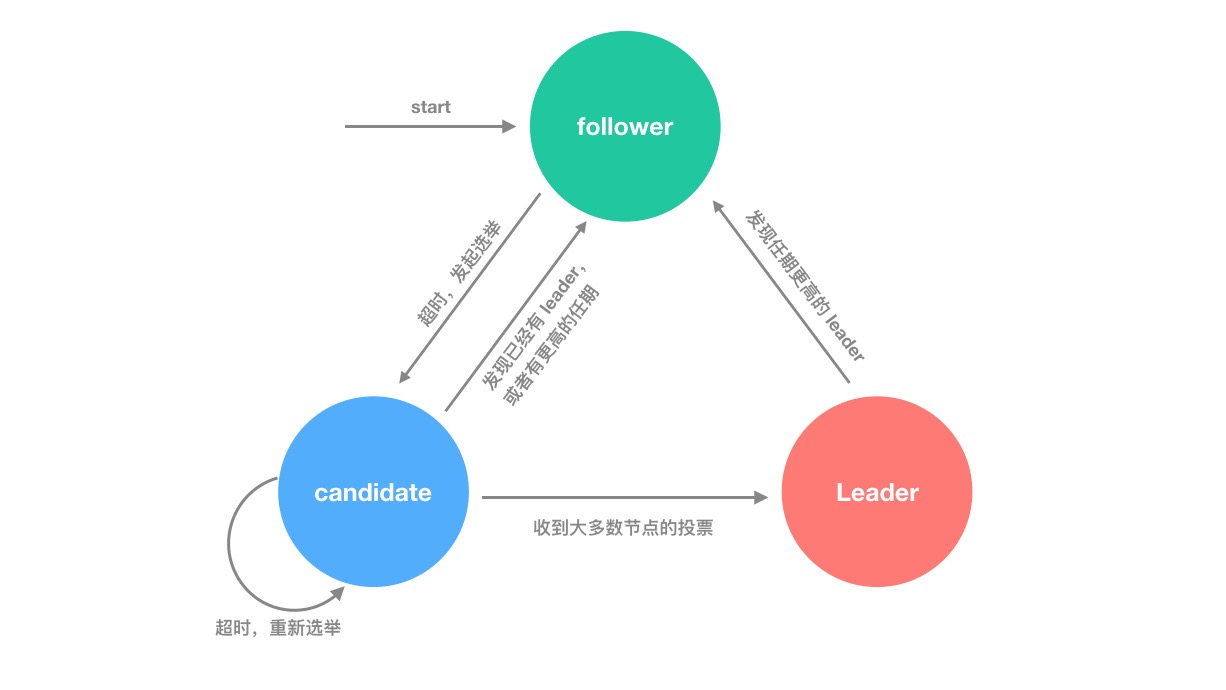
在 Raft 算法通过日志复制来保证系统中各个节点之间的数据一致性,领导者会向其他节点发送日志条目,其他节点会将这些日志条目添加到自己的日志中,并向领导者发送确认消息,当所有节点将日志条目持久化并且发送确认消息之后则认为这条数据状态一致性得到保持,至于实现细节可以查看文末,我列出的 Raft 协议相关文章。
不可抗拒因素
- 网络分区
- 垃圾回收
- 基于时间
对于分布式系统网络故障,目前最常见的解决方法为负载均衡、主从复制,这些典型案例为 web 应用服务器通过 nginx 做负载均衡,一台服务器出现了故障之后另外一台服务器还能正常工作;主从架构典型应用为 Redis 哨兵模式和 Linux 网络中所有的多网卡绑定设计,都是用来解决网络故障引起系统故障。
在开发单体应用的 web 的时候会对 http 请求延迟做测试,如果延迟过长客户端会无法加载出来数据,而这些问题也是数据包在网络中传输延迟导致的。同理在分布式中检查故障的手段也是基于时间和超时控制的,如何设置超时时间窗口又带来一个新的问题?设置过短导致网络频繁,设置过长又导致出现了故障不能立马检查到。
- 交换机故障
- 程序高负载
- 虚拟化环境 CPU 切换资源延迟
- 基于有 GC 的语言出现 STW 情况
假设现在不同考虑到网络可靠性问题了,数据包能在规定的时间内到达分区节点中,现在剩下的问题为服务器本身和应用程序本身的问题,不同的时区的分区节点如何做时间的协调工作,这种最为常见解决方法是通过时间戳的方式,例如两个客户端同时向分布式数据库写入一条数据,谁会优达到呢?这很难受,取决于服务端如何处理,例如服务器的程序正在做 GC 垃圾回收,导致整个进程出现了 STW 状态,当进程苏醒时时间就会存在偏差了。
针对于进程内的 GC 导致程序停止问题,和磁盘 IO 读写导致程序阻塞问题影响的涉及时间偏差问题,目前解决方案是使用无 GC 编程语言,或者对 GC 参数做设置,例如 Java 最新版本采用 ZGC 设计方案,或者使用 Rust 这种特殊内存管理的编程语言进行编写应用,针对分布式常见可以采用滚动停机方法进行 GC 回收,当要进行垃圾回收时把执行任务节点从集群剔除,这也是一种常见的做法。
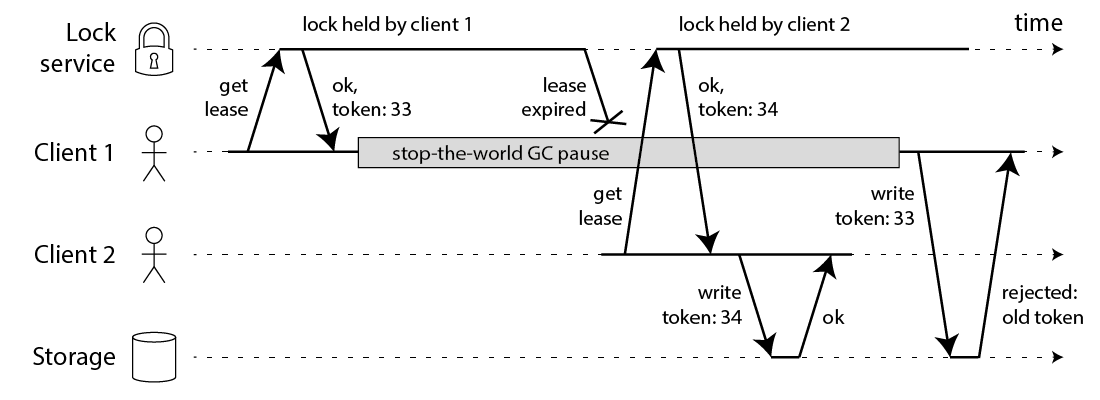
不可靠因素太多,怎么确定集群中的数据分区问题?故障检查问题?单靠节点自身来检查是完全不够的,而且网络波动导致分区故障,在同一个地区服务器可能会检查到,其他地区服务器因为网络线路原因导致不能监测到,目前最好办法为法定人数来解决,多个节点对一个节点做仲裁,如果集群中的三分之二节点认为某个节点挂了,那么它就真的挂了,即使它进程正在做 GC 垃圾回收处于假死状态,也等同于从集群中移除废除它的工作职责,目前实现这些算法的常用的为 raft 协议和 quorum 协议,以法定人数来解决这些问题。

