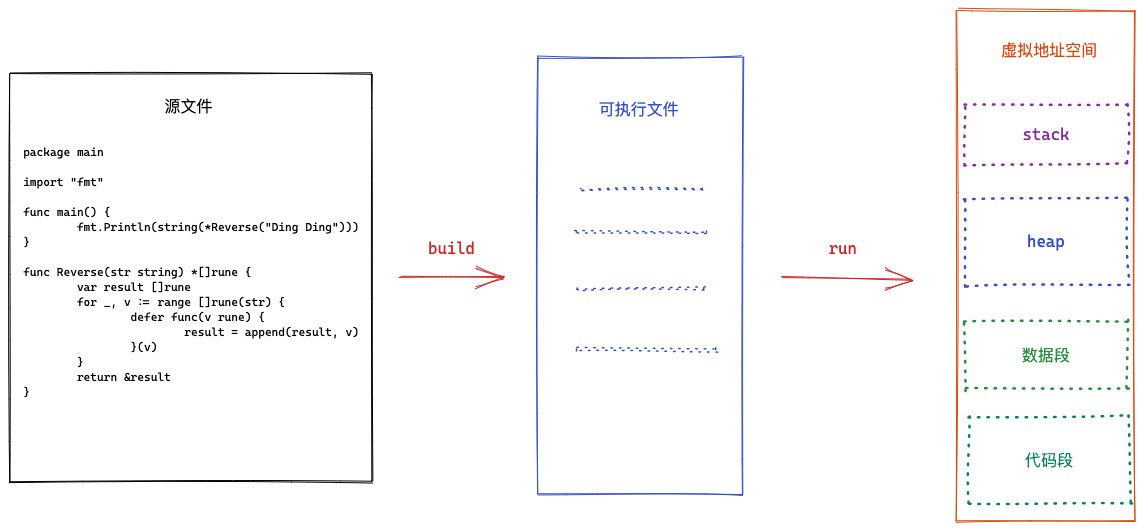
前 言
很多时候为了更快的开发效率,大多数程序员都是在使用抽象层级更高的技术,包括语言,框架,设计模式等。所以导致很多程序员包括我自己在内对于底层和基础的知识都会有些生疏和,但是正是这些底层的东西构建了我们熟知的解决方案,同时决定了一个技术人员的上限。
在写 C 和 C++ 的时候动态分配内存是让程序员自己手动管理,这样做的好处是,需要申请多少内存空间可以很好的掌握怎么分配,但是如果忘记释放内存,则会导致内存泄漏。
Rust 又比👆上面俩门语言分配内存方式显得不同, Rust 的内存管理主要特色可以看做是编译器帮你在适当的地方插入 delete 来释放内存,这样一来你不需要显式指定释放, runtime 也不需要任何 GC ,但是要做到这点,编译器需要能分析出在什么地方 delete ,这就需要你代码按照其规则来写了。
相比上面几种的内存管理方式的语言,像 Java 和 Golang 在语言设计的时候就加入了 Garbage Collection 也就 Runtime 中的 gc ,让程序员不需要自己管理内存,真正解放了程序员的双手,让我们可以专注于编码。
函数栈帧
当一个函数在运行时,需要为它在堆栈中创建一个栈帧(stack frame)用来记录运行时产生的相关信息,因此每个函数在执行前都会创建一个栈帧,在它返回时会销毁该栈帧。
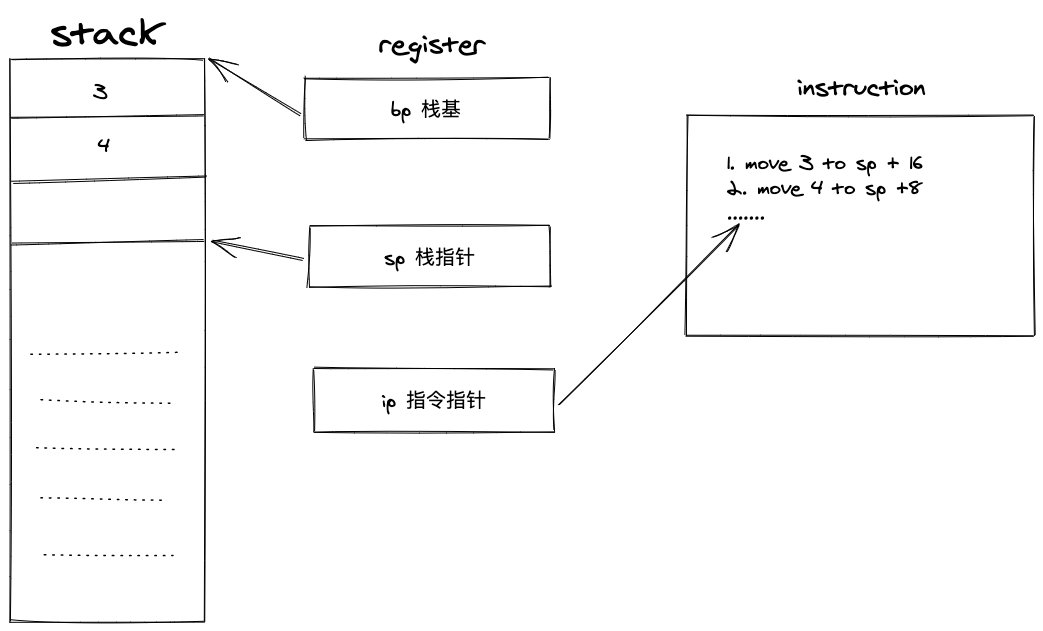
通常用一个叫做栈基址(bp)的寄存器来保存正在运行函数栈帧的开始地址,由于栈指针(sp)始终保存的是栈顶的地址,所以栈指针保存的也就是正在运行函数栈帧的结束地址。
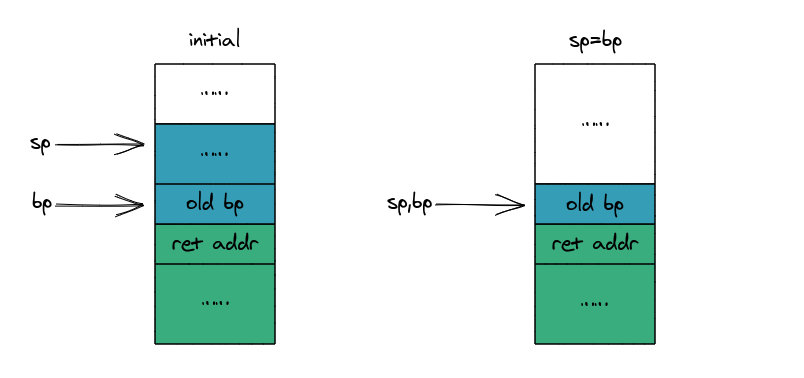
销毁时先把栈指针(sp)移动到此时栈基址(bp)的位置,此时栈指针和栈基址都指向同样的位置。
Go内存逃逸
可以简单得理解成一次函数调用内部申请到的内存,它们会随着函数的返回把内存还给系统。下面来看看一个例子:
package main
import "fmt"
func main() {
f := foo("Ding")
fmt.Println(f)
}
type bar struct {
s string
}
func foo(s string) bar {
f := new(bar) // 这里的new(bar)会不会发生逃逸???
defer func() {
f = nil
}()
f.s = s
return *f
}我想很多人认为发生了逃逸,但是真的是这样的吗?那就用 go build -gcflags=-m escape/struct.go 看看会输出什么???
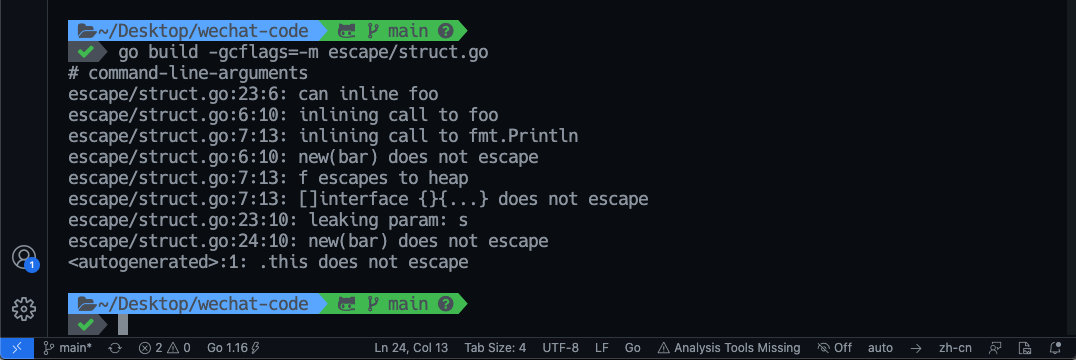
其实没有发生逃逸,而 escape/struct.go:7:13: f escapes to heap 的逃逸是因为 动态类型逃逸 , fmt.Println(a …interface{}) 在编译期间很难确定其参数的具体类型,也能产生逃逸。
继续看下面这一个例子:
package main
import "fmt"
func main() {
f := foo("Ding")
fmt.Println(f)
}
type bar struct {
s string
}
func foo(s string) *bar {
f := new(bar) // 这里的new(bar)会不会发生逃逸???
defer func() {
f = nil
}()
f.s = s
return f
}f := new(bar)会发生逃逸吗?
$: go build -gcflags=-m escape/struct.go
# command-line-arguments
escape/struct.go:16:8: can inline foo.func1
escape/struct.go:7:13: inlining call to fmt.Println
escape/struct.go:14:10: leaking param: s
escape/struct.go:15:10: new(bar) escapes to heap ✅
escape/struct.go:16:8: func literal does not escape
escape/struct.go:7:13: []interface {}{...} does not escape
<autogenerated>:1: .this does not escapeGo 可以返回局部变量指针,这其实是一个典型的变量逃逸案例,虽然在函数 foo() 内部 f 为局部变量,其值通过函数返回值返回,f 本身为一指针,其指向的内存地址不会是栈而是堆,这就是典型的逃逸案例。
那就继续往下看吧,看看这个例子:
package main
func main() {
Slice() // ??? 会发生逃逸吗?
}
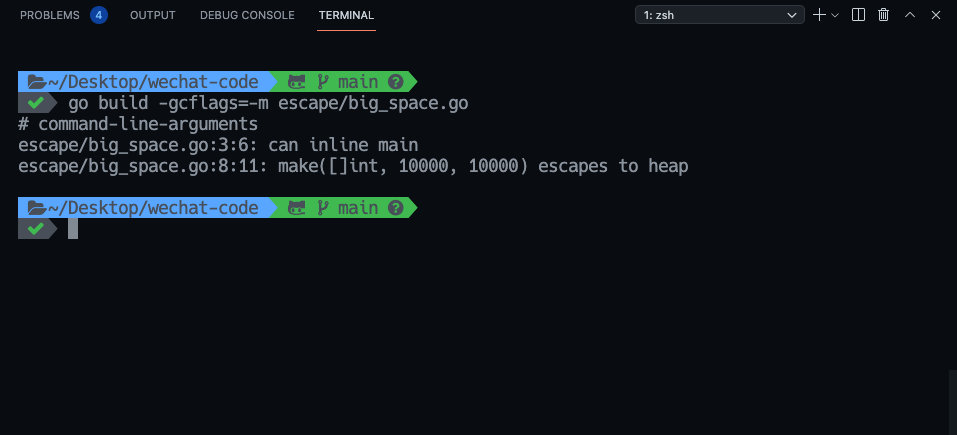
func Slice() {
s := make([]int, 10000, 10000)
for index, _ := range s {
s[index] = index
}
}
估计很多人会回答没有,其实这里发生逃逸,实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
最后一个例子:
package main
import (
"fmt"
"io"
"os"
)
func main() {
Println(string(*ReverseA("Ding Ding"))) // ???
}
func Println(str string) {
io.WriteString(os.Stdout,
str+"\n")
}
func ReverseA(str string) *[]rune {
result := make([]rune, 0, len(str))
for _, v := range []rune(str) {
v := v
defer func() {
result = append(result, v)
}()
}
return &result
}
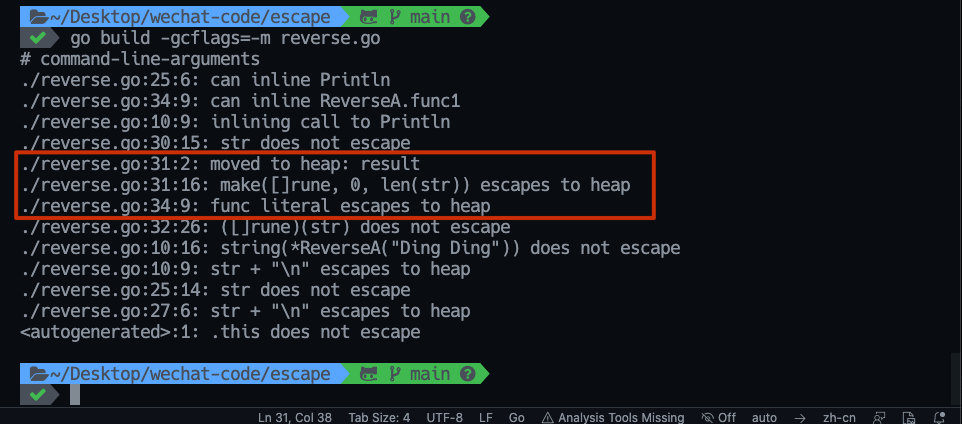
如果一个变量被取地址,通过函数返回指针值返回,还有闭包,编译器不确定你的切片容量时,是否要扩容的时候,放到堆上,以致产生逃逸。
于是我优化了一下代码,再看看
package main
import (
"io"
"os"
)
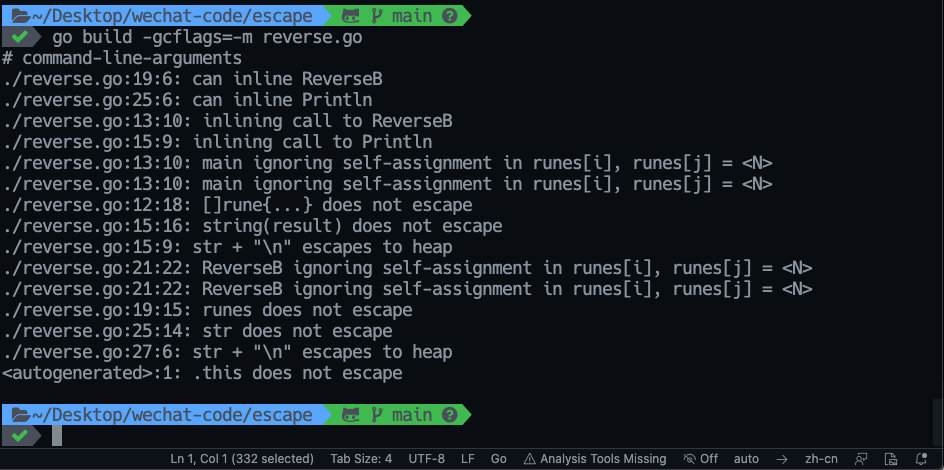
func main() {
result := []rune("Ding Ding")
ReverseB(result)
Println(string(result))
}
func ReverseB(runes []rune) {
for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
runes[i], runes[j] = runes[j], runes[i]
}
}
func Println(str string) {
io.WriteString(os.Stdout,
str+"\n")
}
如何得知变量是怎么分配?
引用 (golang.org) FAQ官方说的:准确地说,你并不需要知道, Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。知道变量的存储位置确实和效率编程有关系。如果可能, Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上, 然而,如果编译器不能确保变量在函数 return 之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。
小 结
- 逃逸分析的好处是为了减少 gc 的压力。
- 栈上分配的内存不需要 gc 处理。
- 同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。

