现在计算机架构都是多核CPU架构,面对多核架构的计算机在操作系统设计就要引入多任务处理设计,让程序能发挥多核计算能力;程序在计算机上运行一次的单位是进程,进程是操作系统为每个程序分配的资源调度的基本单位;早期的计算机是面向过程的,也就是每运行一次程序,程序就是基本的执行实体,然后程序结束就停止了计算机,但是在现在计算机中进程更多的是一个容器的概念,进程里面可以创建很多的线程,而这些线程属于进程,也就是多线程技术。
线程是计算机中CPU任务调度的基本单位,而进程是程序拥有系统硬件资源的单位;
进程调度
程序本身就是被打包的二进制可执行文件也就是机器能认识的指令集合,静态文件,在我们没有打开程序的时候这些文件会存放在硬盘中,当我们打开程序时就会操作系统加载到内存中开始由CPU去执行指令,从而达到我们编写的逻辑运算。
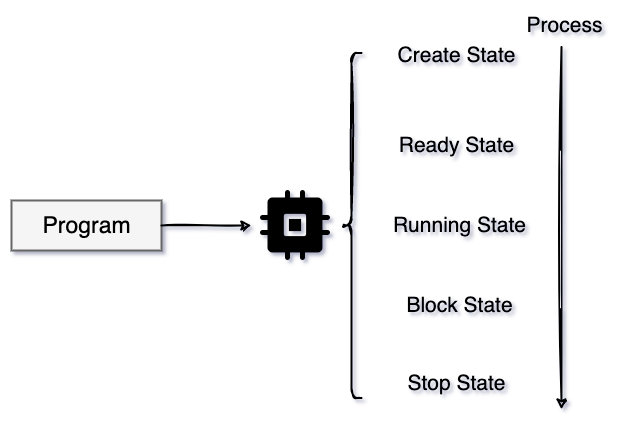
而相对程序被加载到内存中开始由CPU执行的过程,这个过程就叫作process有操作系统调度并且管理的着,进程在运行中是动态的,同一个程序多次被执行也是会创建多个进程的,每个进程都会自己的唯一身份ID,也是PID;
早期单核的CPU一次只能执行一个任务,想要实现多任务,需要把 CPU 的运行时间切成一段一段的时间片,每个时间片运行一个程序,循环的分配时间片给不同的应用程序,由于时间片非常的短,在用户看来,就像是多个任务同时在运行。
在计算机的世界里,内核把CPU的执行时间切分成许多时间片,比如1秒钟可以切分为100个10毫秒的时间片,每个时间片再分发给不同的进程,通常,每个进程需要多个时间片才能完成一个请求。这样,虽然微观上,比如说就这10毫秒时间CPU只能执行一个进程,但宏观上1秒钟执行了100个时间片,于是每个时间片所属进程中的请求也得到了执行,这就实现了请求的并发执行。
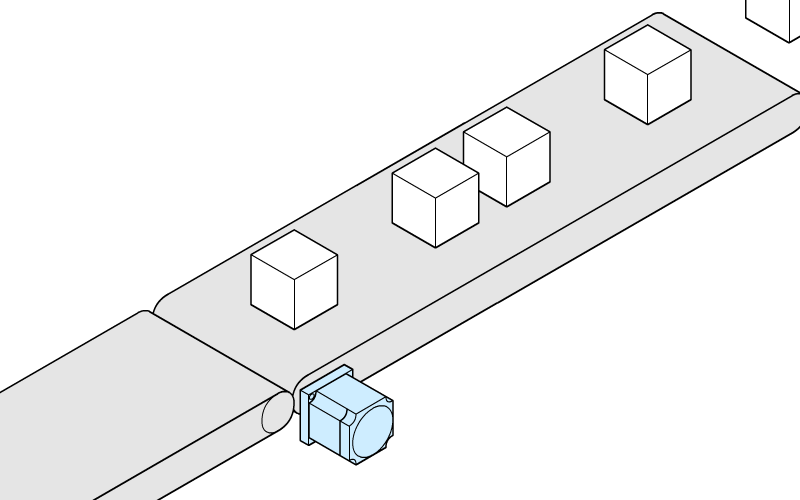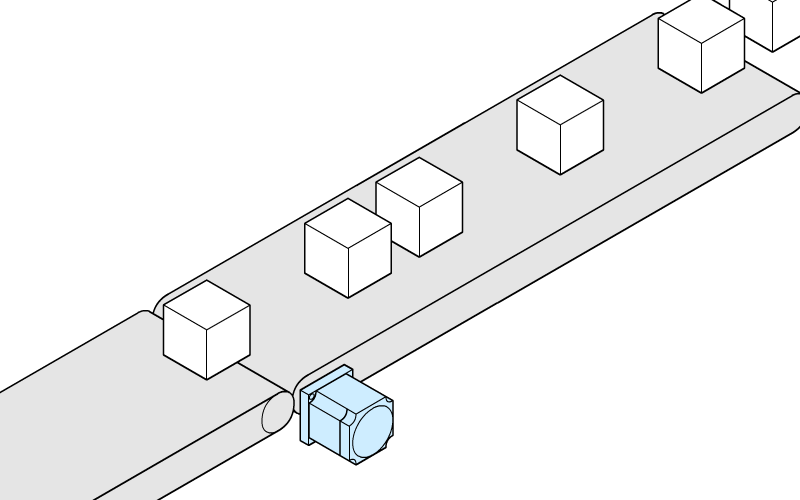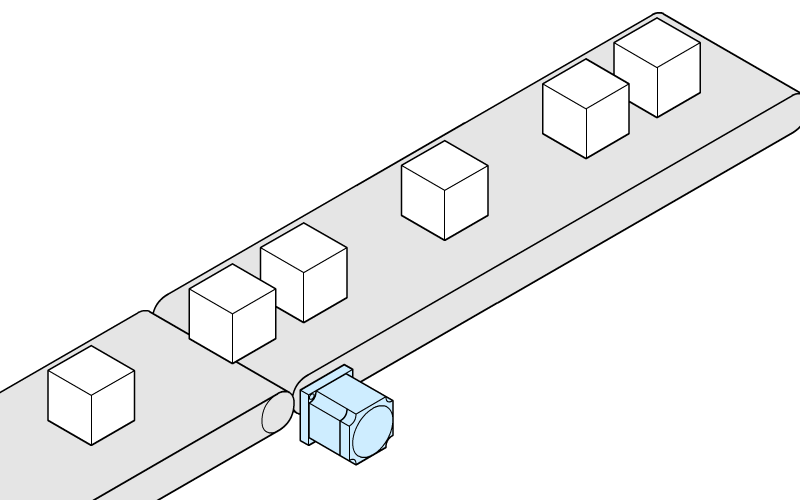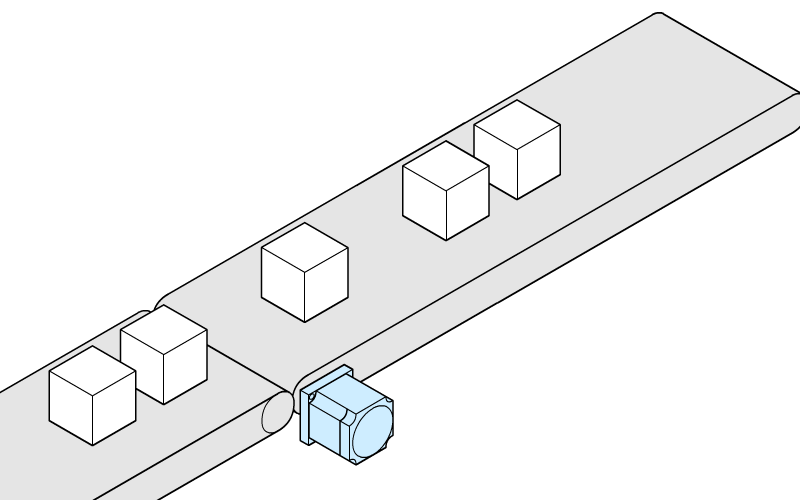
CPU就好像一个流水线上的工人,不断的处理流水线上的各种信息包裹,打开包裹读取指令并执行,遇到执行慢的IO调用(或执行时间片结束)则会暂时把它放到等候区,继续处理流水线上下一个等待处理的包裹。等候区有很多这样的包裹,等待着系统的IO执行完成,当IO调用结束后,又开始进入到等待处理队列。
进程状态
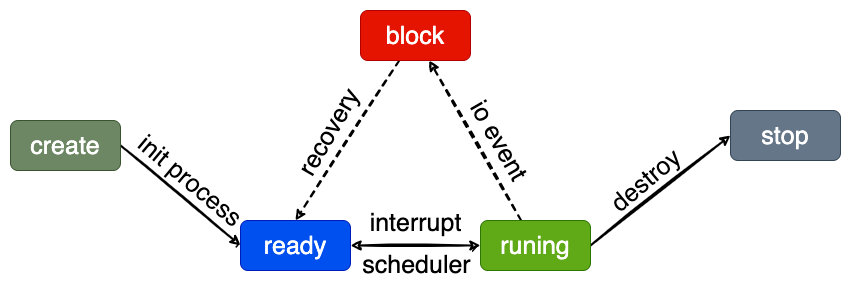
当一个程序被打开创建进程的之后要根据操作系统的调度来完成状态的切换,如果进程本身逻辑没有去阻塞IO相关的事件,正常就是按照操作系统的分时调度规则来运行进程,如果发生了IO阻塞那么进程就会陷入阻塞状态,或者被操作系统中断去执行其他进程。在操作系统之上有很多的进程而不是单一一个进程独占着系统调度资源。
例如有一段程序代码如下要通过控制台读入信息,这时运行程序如果我们不输入内容,那么程序就要等待IO事件:
func main() {
var (
name string
age int
is_marry bool
)
fmt.Scan(&name, &age, &is_marry)
fmt.Printf("名字:%s 年龄:%d 已婚:%t \n", name, age, is_marry)
}调度图如下:
一个进程的内存布局有:数据段、代码段、用户栈、用户堆、代码库、内核空间;数据段和代码段是从程序存储在静态文件中加载到内存中,并且数据段是伴随着进程运行到销毁的全局变量。
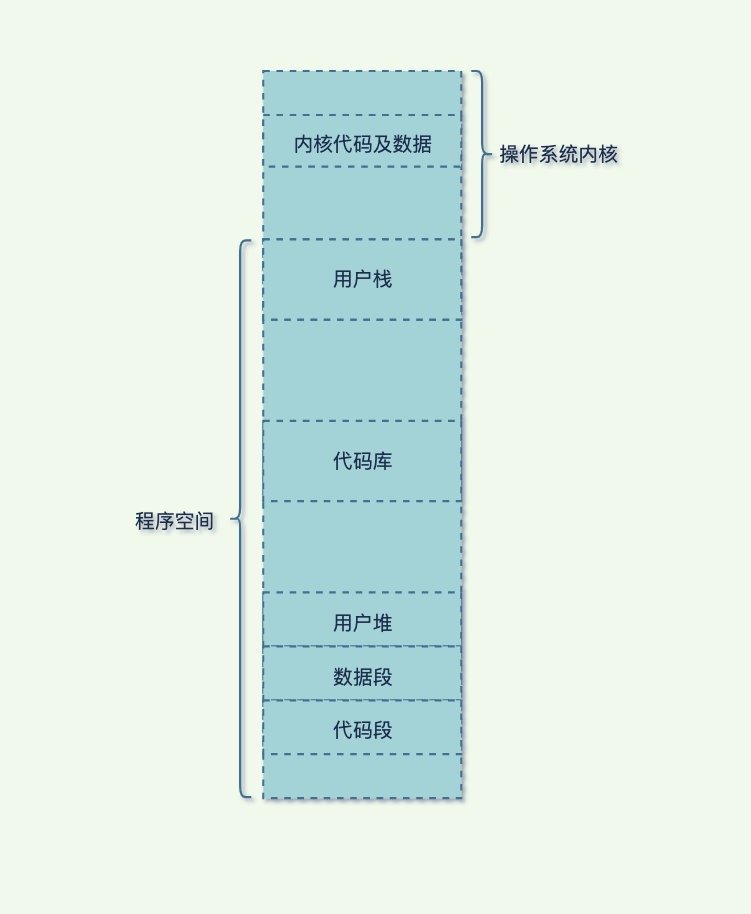
- 用户栈:栈中保存的是进程需要使用的各种零时变量数据,栈是一种可伸缩结构,自顶向下,栈底在高地址位上,栈顶在底地址位上,当输入被压入栈的时候栈顶会向下移动,当数据被销毁时栈就会收回去;
- 代码库:一般都是操作系统上的libc静态链接库,方便程序导入使用的,这些代码库会映射到用户栈下面的地址空间作为只读的方式;
- 用户堆:进程执行的时候可能要动态创建新的内存,这时内存分配区域就是用户堆上进行的,堆顶在高地址位上,堆的扩容方式是自底部向上扩容的;
- 代码和数据段:主要是一些二进制静态文件里面中的内容,当操作系统开始创建本程序的进程的时候就会被加载到内存中,数据段主要是全局静态的变量值,而代码段就是一直编译好的二进制指令;
还有一部分就进程顶部的内存映射,这部分的内存映射地址和实践物理地址是一致的,但是对用户进程内部是不看见的。这部分的内存是方便进行内存管理,内核部分也有栈空间是给操作系统使用的,还有数据段和代码段,当程序发生了中断,就会进入内核态进行执行,这部分内存保存一些进程执行寄存器上信息传递给操作系统;Linux使用下面命令就可以查看某进程的内存布局情况:
cat /proc/PID/maps不会看到进程内核段的内存映射,因为这部分是对用户态进程屏蔽的。
上下文切换
随着多核CPU架构的出现,现在操作系统要充分发挥这些多核CPU架构就必须要加入多任务调度系统,换到用户态程序来说就是要支持多进程之间的调度工作;还有上面也说到当进程出现了IO阻塞事件,等待阻塞着就不能占用浪费CPU资源,此时就应该去调度其他的进程任务放到CPU去执行,这才是高效的任务调度设计。
开发经常使用的Linux就是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉;而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器Program Counter PC;
在多任务切换的时候,操作系统就要保存当前进程的寄存器和程序计数器的信息,用来存储CPU执行的指令的位置还有下一条指令的位置;CPU在运行进程的时候都需要这些信息,所以每次切换必须将这些信息保存起来,在操作系统设计上有一个叫PCB的模块负责整个工作。
PCB Process Control Block的工作原理: 在运行下一个进程之前,先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。 而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行,下图就是我画的一个切换流程:
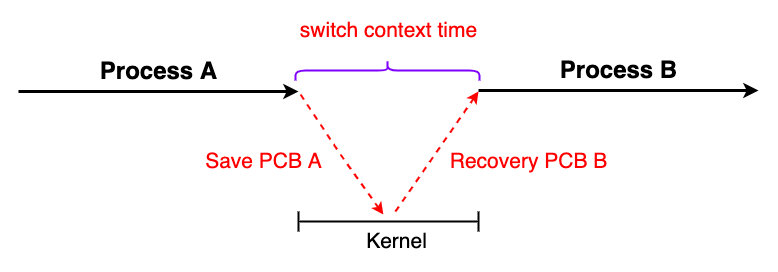
根据Tsuna的测试报告,每次上下文切换都需要几十纳秒到数微妙的 CPU 时间。这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也是导致平均负载升高的一个重要因素。
触发上下文切换的因素有很多,例如:
- 操作系统分配的时间片耗尽了,被系统挂起操作;
- 进程在调用系统资源,系统调用,得到恢复;
- 进程主动调用sleep,主动让出执行权限;
- 操作系统调用其他优先级较高的进程;
- 发生硬件中断时,进程会被中断挂起,转而执行内核中的中断服务程序。
状态控制
进程的状态控制实现就依赖于PCB,当有进程被创建的时候就会创建一个PCB,这个PCB会被加入到就绪队列中,然后等待CPU去执行;在操作系统中维护了多个PCB队列,分别对应着最上那副流程图上5个步骤,也就是5个不同状态PCB队列,下面为运行过程中最常见的3种状态:
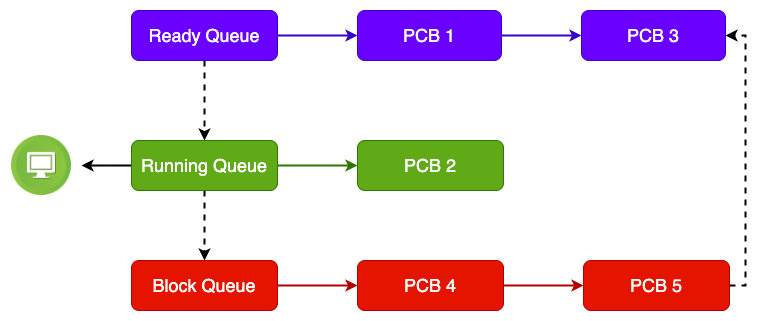
当上下文切换的时候,PCB的状态变更都会是使用内核的原语进行的,实现原语的指令有:开中断,闭中断;这两条特权指令组成状态切换时不可以被其他中断打断,原子的完成PCB状态的转换并且要转换队列,从阻塞队列到就绪队列一定要是原子操作,不然就出现了队列里面的PCB状态和当前队列类型不一致;
进程树
操作系统提供创建进程的系统调用函数,这个根据不同系统实现各有不同的,在Linux中创建一个进程使用的fork函数接口,这个函数会把当前进程创建一个一模一样的子进程出来;每个进程信息会对应着task_struct,并且会记录父子进程之间的关系;
下面是一个Linux操作系统进程树组织管理图,当系统内核创建完成会创建一个init进程,这也是所有进程的祖先也就是根进程:
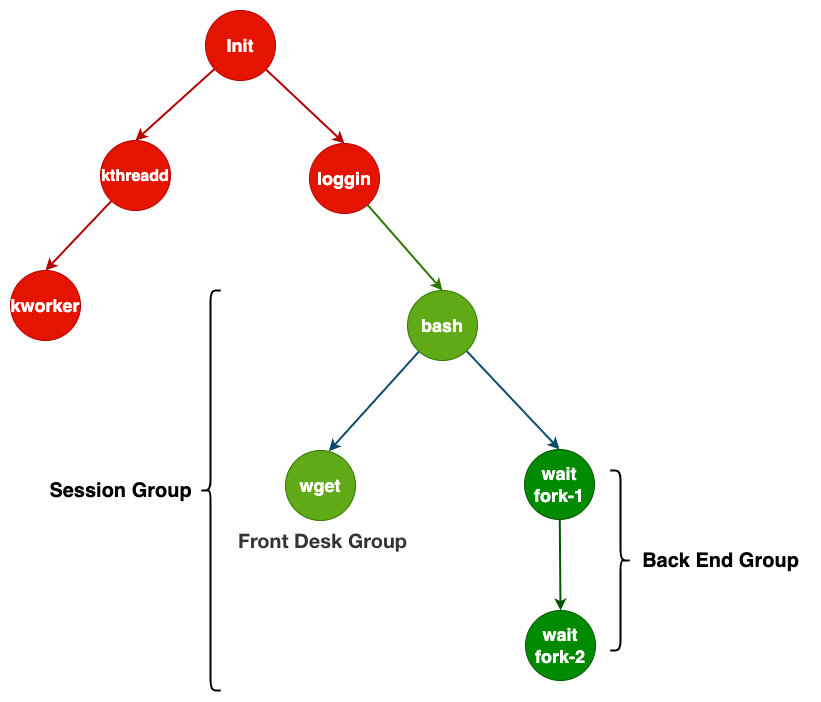
第一个进程是init,init进程在初始化完毕后面会创建一个kthreadd进程负责所有关于内核相关的进程管理工作;在初始化完内核相关的工作之后会创建一个login进程来监听处理来自要登录到系统的用户,如果有用户登录成功那么会创建一个bash进程,前台运行着接收用户输入的所有相关的操作指令,内核进程就负责辅助这方面相关的工作,管理、调度、监控、回收、信号处理工作;如上图绿色部分为一个用户会话,有前台和后端经常区分;
创建进程方式有很多第一种就是通过fork方式分裂出来一个进程;还有一种就是Linux提供的exec接口,exec系统调用可以把静态二进制文件传入到参数里面创建出新的进程;
进程组是一组进程集合,多个进程组成的信息都是互相共享的,这个基于同组信号量操作;子进程结束之后是不会自动回收对应的内存的,会一直占用资源,除非调用wait操作;
数据共享
进程间的数据共享问题,目前解决方案就是:共享内存、消息通讯;这两种模式;两种又分布不同两大类,共享数据:
1. 基于数据结构共享 (限制大小数组)
2. 基于存储区的共享 (内存划分一块存储区)
在上面介绍了进程地址空间都是隔离起来的,不能互相访问,如果能直接互相方面那么就麻烦,所有想共享内存那么就得通过内核来辅助完成数据共享;操作系统会在内核部分共享这区域,但是该区域会互斥同一时间只能一个进程进去访问,这也是并行安全性问题。
消息传递: 也是多种,这里如果了解过erlang或者go语言的话,他们并发程序之间的消息通讯就是基于消息传递模型的,只是实现部分不一样:
1. 直接通讯
2. 间接通讯
消息通讯方式可以在内存中开辟pipe,通过管道来通讯,管道分别为:半双工通讯,某一时间段只能实现单向的传递,如果能实现双向的同时通讯那么就要2个管道;其实就是一个双端阻塞队列。
消息通讯设计具体实现在这个两个模型上有很大的差异,CSP模型和Actor模型:
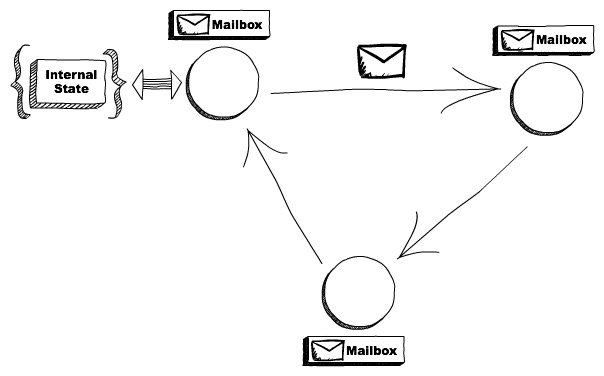
Actor模型: 可以看做是消息的间接式通讯,类似于MQ订阅和消息消费一样,生成把消息生产到指定邮箱里面,然后消费者去拉取;
CSP模型: 可以认为是一种双端阻塞队列数据结构的共享,同缓冲区来获取和发送消息,Go的CSP模型应用。

