什么虚拟线程?虚拟线程是一种在用户态下创建一种更轻量级的线程的方式,很多语言都支持了这一特性例如:Go、Kotlin、Erlang、Rust中的第三方运行时tokio等。要解决共同的问题是怎么在有限的内核线程数下提高程序的吞吐量,并且可以减少维护多线程并发程序的工作量,可以更快的创建需要管理的并发任务。
传统线程
传统操作系统和用户程序的线程模型是1:1,也就是用户程序创建一个线程对应内核程序也有一个线程,这样的做法我之前写的文章有过介绍,随着用户态线程的增加操作系统内核线程也会增加,并且任务调度属于操作系统进行管理,无法控制调度任务优先顺序。
服务器应用程序通常处理相互独立的并发用户请求,因此应用程序通过在请求的整个持续时间内将线程专用于该请求来处理请求是有意义的。这种线程每请求风格易于理解、易于编程、易于调试和分析,因为它使用平台的并发单位来表示应用程序的并发单位。
服务器应用程序的可扩展性遵循利特尔定律Little’s Law,它与延迟、并发和吞吐量有关:对于给定的请求处理持续时间(即延迟),应用程序同时处理的请求数(即,并发)必须与到达速率(即吞吐量)成比例增长。例如,假设平均延迟为50ms的应用程序通过同时处理10个请求,实现每秒200个请求的吞吐量。为了使该应用程序扩展到每秒2000个请求的吞吐量,它需要同时处理100个请求。如果每个请求在请求的持续时间内都在线程中处理,那么,要使应用程序跟上,线程数量必须随着吞吐量的增长而增长。
不幸的是,可用线程的数量是有限的,因为常用的编程语言都是在操作系统线程之上包装的实现,操作系统线程成本高昂,我们编写的应用程序大多数都是网络应用程序,要处理很多读写任务,负责程序的分布式计算任务,但是这些多任务处理在传统1:1线程模型中是由操作系统管理的;我们程序员往往在编写程序的时候都知道自己编写的逻辑在什么时候会会发什么处理任务逻辑,应该怎么去调度这个任务,但是对于操作系统来说它完全不知道如何去调度优先权较高的任务,除此之外发生上下文切换开销也会影响程序,如果能把大量调度任务控制在用户态线程那么就很好解决这个问题了。
生产者消费者模型
在并发应用程序设计有一个数据处理模型叫:生产者和消费者 模型。这个模型可能说起来一部分开发者不知道,不过相信很多人在业务开发过程中使用过MQ(消息队列),让两个系统之间传递消息来处理数据,这个应该有用过,这个也可以看做生产者和消费者模型应用。
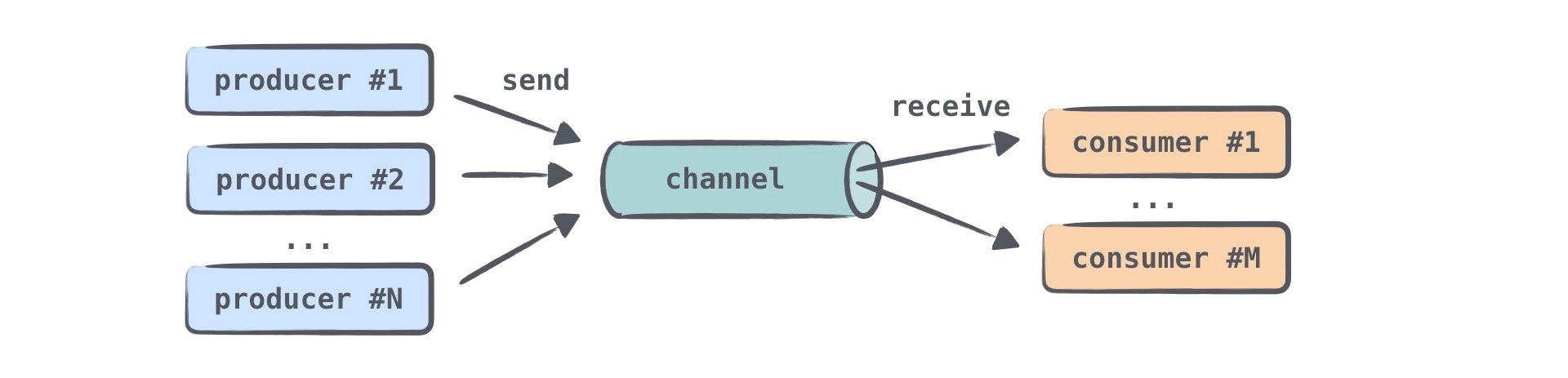
原理就是通常我们会编写一个用于数据生成的一端程序,然后在使用一个数据缓冲区的通道来保存被生产的数据,另外一端程序就从通道里面拿取数据并且使用,被拿走的数据就不会再被管理的存放被消费者消费掉了,这就是一个生产者和消费者并发模型,如下图:

例如下面一个例子,就是启动一个协程去往消息通道里面发送数据,然后从另外一边消费数据:
package main
import "fmt"
// Prints a greeting message using values received in
// the channel
func greet(c chan string) {
name := <- c // receiving value from channel
fmt.Println("Hello", name)
}
func main() {
// Making a channel of value type string
c := make(chan string)
// Starting a concurrent goroutine
go greet(c)
// Sending values to the channel c
c <- "World"
// Closing channel
close(c)
}如果生产者对应一个线程,消费者对应的一个线程,如果在单核心处理器上也就是传统调度器出来会对应这一个内核线程,当生产者和消费者同时进行并发的时候,单核就要发送至少一次上下文切换工作才能正常消费数据,达到生产者和消费者两个角色的转换,如下图:
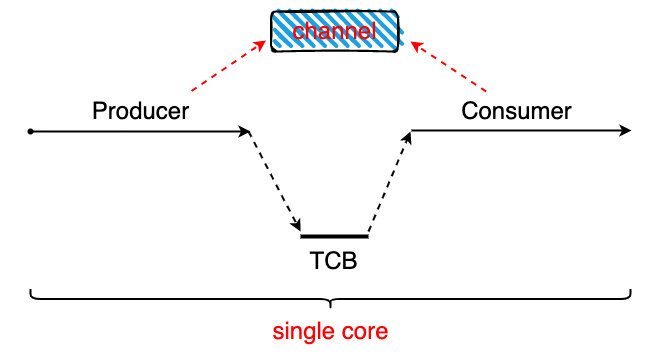
像上面这样完成生产和消费要切换一次上下文,实际上操作系统的调度器不会就这么认为这两个线程存在生产者和消费者的关系,因为操作系统上还有其他的进程,当生产者生产了数据之后我们程序员理想的状态是马上就能被消费,但是操作系统可不会这么去调度,无法确定线程之间的工作关系,所以这时就得弄一种能被用户态下的线程调度器实现。
协程设计
上面所说的尽管生产者早已完成了数据的生成,但是消费者会可能因为延迟而不能及时处理这些缓冲区的数据,为了消除调度延迟,这时又证明计算机科学界的一句话:计算机科学中遇到的所有的问题都可以使用一个中间层来解决。
协程就在用户态线程基础之上实现一个用户态下的调度器模型,通过用户态下的线程本地栈来保存任务的上下文,就可以避免触发用户态到内核态切换延迟了。
但是光光这个是不够了,为什么不够?之前我的文章我就介绍过当进程触发一次IO操作的时候,往往IO系统调用不能立马返回,而是要阻塞。此时如果线程一直占用CPU就算浪费CPU资源,应该把当前线程切换到阻塞状态,然后从就绪TCB队列中取一个线程继续放到CPU上执行,这样才能利用好CPU的调度资源。
为此很多编程语言设计者都想在语言层面解决这些问题,这里我就拿我熟悉的Go语言为例,Go语言的设计者在语言的运行时上加入了虚拟线程的设计概念;在运行中设计一个复杂的用户态下的任务调度器,绑定在操作系统之上来屏蔽操作系统调度器对普通线程的干扰,虚拟线程调度器是一个非常复杂的软件,我上一篇在多线程并发模型哪一张我介绍了。
GMP调度器
本节会介绍Go语言具体的调度器怎么去实现,Go语言的运行时调度器会将操作系统的线程其自己的逻辑处理器绑定,并在逻辑处理器上运行而是提供用户态代码实现的,这个逻辑处理器可以让用户把代码逻辑块包装成任务放到自己的任务队列处理。
Go的GMP调度器基本架构是:将用户态的一个线程M和内核线程绑定,然后Go在内部将用户态线程M绑定到自己实现的处理器上,也就是逻辑处理器,这个处理器负责从任务队列中拿取任务分片分时调度执行。如果遇到一些IO阻塞任务会把当前执行的任务开创一个新的M线程挂载上,等待线程达到满足条件后将其放到本地队列中,方便后面进行被调度,而此时的用户态线程会把放回线程池方便后面继续使用,如下图:
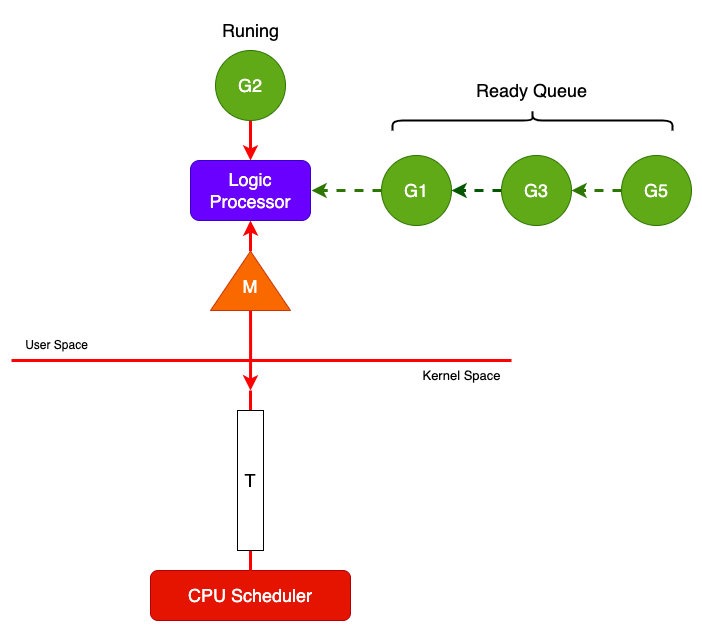
默认GMP的调度器可以无限的创建逻辑处理器,但是运行时会限制用户态下的线程数量,这里我不太清楚,但是我在《Go in action》这本书找到说是最大上线是1000用户态线程,不过可以通过在runtime/debug包里面的SetMaxThreads方法来设置新的线程上限。
GMP调度器在多核处理器上执行任务是并行,并行是可以在同一时间内处理多个任务,例如边跑步边听单词;而并发是在某一段时间内,把时间分成多个段落来执行任务,但是这是有一个前提的需要在多核CPU上,如果物理CPU是单核还是会被实为并发的方式处理。
Go的调度器上的任务也有阻塞态、运行态、就绪态,当创建需要创建一个任务的时候,就可以使用go关键字将要运行的逻辑代码块包装成一个任务,这是Go的调度器会默认去执行这个任务块,如下代码:
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("commit a task")
}()
wg.Wait()
}在线运行代码:Go Playground
上面的go func(){}()所创建的任务就会被打包成上图中的绿色部分的G,然后放入调度器队列中被调度执行。
GMP调度算法: 我在有关的文章中找到了一些早年的调度器版本1.5是全局共享一个队列并且默认只会有一个逻辑处理器,但可以使用runtime中的GOMAXPROS函数来设置逻辑处理器的数量。而在1.5往后的版本中把全局队列分成对应的逻辑处理器本地队列,而逻辑处理器数量是默认的CPU核心数,新的调度器架构图:
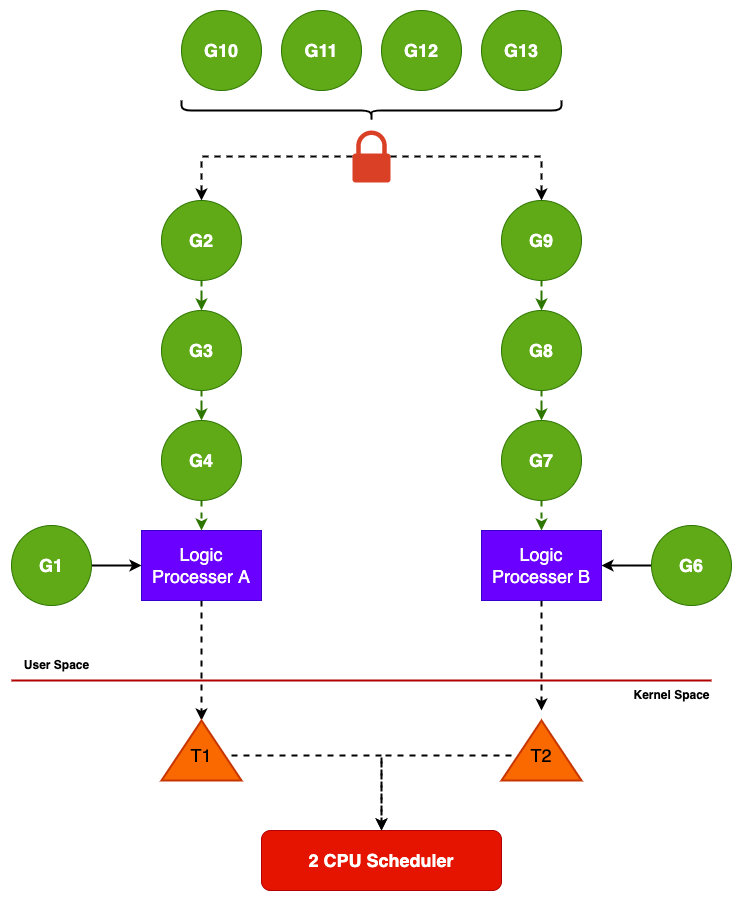
GMP抢占式调度:上图每个逻辑处理器都有本地队列,还有一个全局队列,本地队列是为了缓解全局队列在多个逻辑处理器在去拿取任务时加锁设计的,本地队列可以不需要加锁;另外Go的调度器在设计的时候考虑到了如果本地队列没有可以调度的任务了,那么逻辑处理器可能就会处于空运行的状态,为了解决这个问题调度器策略在本地没有任务执行的时候会去其他队列去拿取一半的任务进行处理,这就是任务窃取调度算法。
抢占式调度work-stealing算法优先级:当一个逻辑处理器处理完所有本地任务之后,就会触发一次任务抢占式调度;优先级如果全局队列有任务的话,先从全局队列中拿取(当前个数/runtime.GOMAXPROCS)个,否则直接从其他逻辑处理器本地任务队列中拿取一半,这里的每个逻辑处理器的本地队列是2^32个。
如果要阅读源代码的话,源代码地址:src/runtime/runtime2.go在这个源代码文件里面对应下面几个结构体:
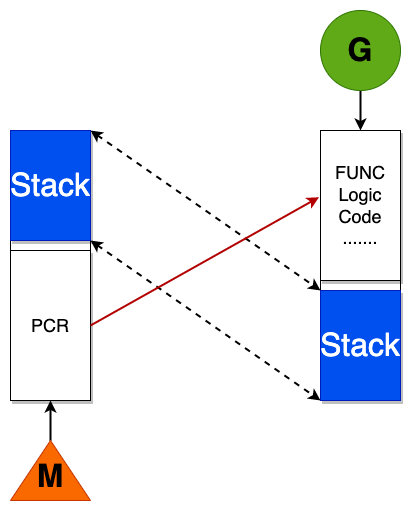
runtime.g结构体就是上图所我画的绿色部分G,包含了当前goruntime的状态、堆栈、上下文信息。runtime.m结构体也就是系统线程,M是一个线程,每个M都有一个线程的栈,如果没有给线程的栈分配内存,操作系统会给线程的栈分配默认的内存,当线程的栈制定,M.stack->G.stack, M的PC寄存器会执行G提供的函数。
可能上面的m和g关系不好理解,看看下面我画的这幅图就可以理解了:
自旋和抢占
上面介绍了Go的基本GMP调度器设计和具体调度算法,但是还有设计细节没有讨论,本节讨论一些抢占式调度。设想一下我们在通过go func(){}创建的任务G,的代码逻辑里面一段如下的代码:
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func () {
defer wg.Done()
loop()
}()
}
func loop() {
for {
fmt.Println("loop...")
}
}如果这个被GMP中P调度执行,那么就会一直占用着逻辑处理器P,为了防止这样的代码和一些占用阻塞时间比较长的G;GMP在设计的时候加入一个叫sysmon的处理器也就是线程,会对全局的P进行定时扫描,如果发现了有这种情况,会把P和当前G剥离出来,把G放到全局队列中,换去执行其他的任务,时间占用不能超过>=10ms。
物理线程自旋(Spining Thread): 设想一下一个物理M线程没有找到能绑定的逻辑处理器也就是P,那么物理线程M就不需要工作,如果不需要工作我之前的文章讲过线程机会进入其他状态,就会发生上下文切换,为了防止上下文切换所有调度器算法会让M进行自旋占用着;
还有一种就是M和P绑定,短暂的不能有G任务需要调度,但是可能这个时间很短,但是过一会儿就会有任务过来,让线程临时自旋一会就可以降低物理线程上下文切换的开销,通过自旋浪费一些CPU资源能让能新创建的goroutine能第一时间被执行,达到提升性能效果。
小结
本文我针对操作系统线程和协程调度算法设计做了一些总结;文中以Go语言的GMP协程调度器的一些架构为例介绍了协程调度算法的实现,当然本文中对GMP的调度算法介绍肯定不是很完全详细的介绍的,Go的runtime会在后面的版本中更新迭代,但是本文的内容可以帮助读者对协程调度的具体实现原理知识的掌握。

