计算机性能是跟随着CPU架构进行发展的,在很久以前的计算机上的CPU计算能力还没有现在这么强,大部分还是单核处理器,计算机能够计算完全是依靠在CPU的,CPU的频率越高计算性能就会有相应的提升,但是会带来另外一个问题就是会发热并且发烫,有能耗墙的问题。不是意味着提升CPU运算频率就能提升计算性能的,相反有能耗问题,这个问题是矛盾的。
虽然摩尔定律说软件的性能问题会被硬件的性能提升而埋没,但是摩尔定律的说法是每两年计算机的硬件性能就会翻一倍,但是放到现在2022年,摩尔定律芯片的工艺纳米数已经达到瓶颈;苹果发布的M1 Max芯片也靠着堆核心数才能有性能上的飞跃;单核有能耗墙问题,那么就可以多弄几个CPU来平摊计算性能,现在CPU都有多个核心组成的,多核心虽然能提升计算机性能但是有随之而来的多核处理器对共享数据的访问问题,数据同步问题,这就是本篇文章要介绍的同步原语。
数据竞争
为了高效的利用CPU资源,操作系统会同时调度多个CPU去执行进程任务,同时进程内部可能也是一个多线程程序。也就是之前的文章介绍的多线程概念,真正意义上的并行处理任务;但是如果多个CPU去访问一个共同的数据资源就会出现数据竞争问题,也就是之前文章讲的类似于:优先级反转问题,为了保证数据的完整性和安全性在操作的时候就需要这些任务进行同步操作。
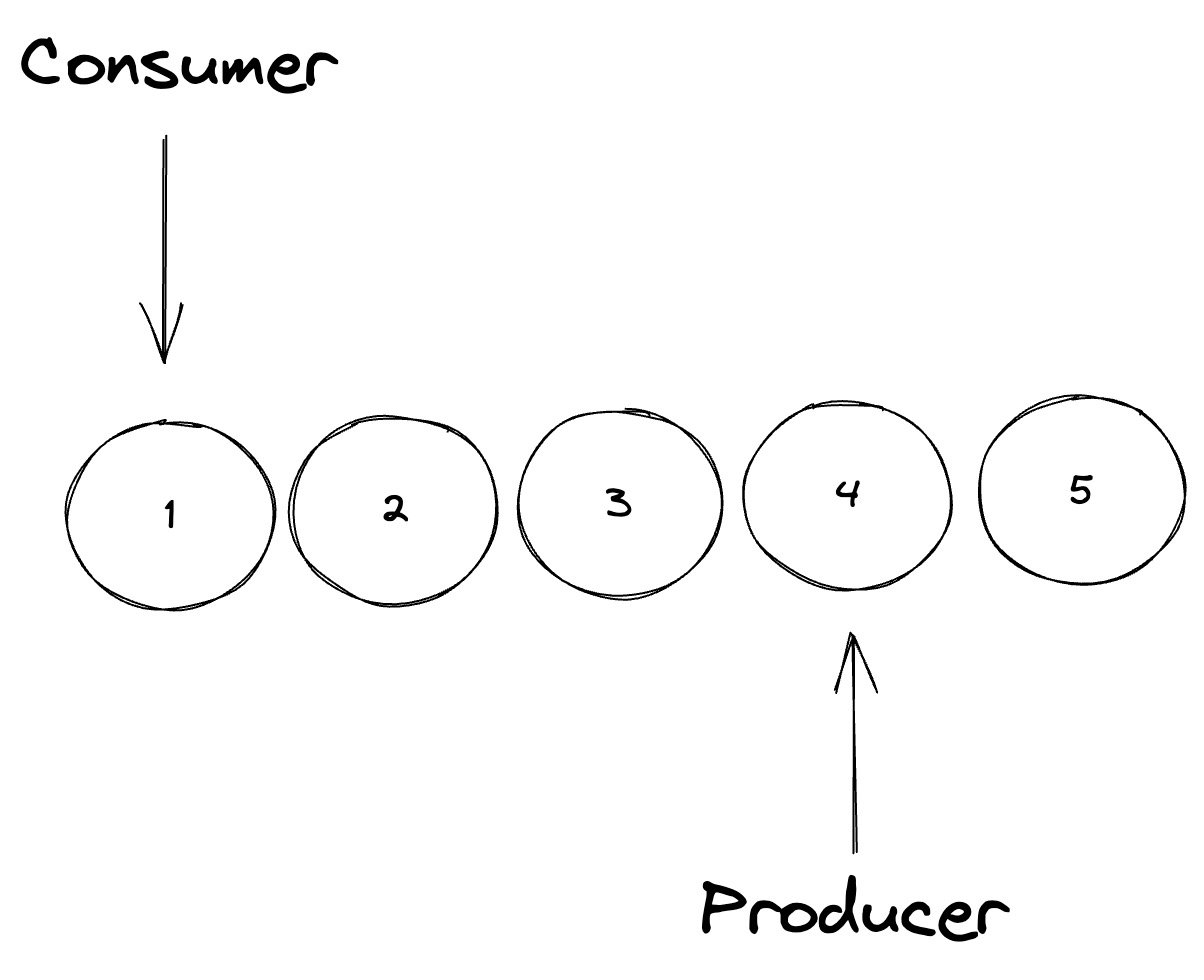
同样还是拿生产者和消费者模型来举个例子,例如上图,现在有两个任务一个为生产者另外一个为消费者,同时在进行缓冲区数据生产和消费的工作,这是1:1的情况下,比多对一好处理;只需要知道缓冲区满了停止生产,缓冲区空了停止消费即可,只需要在内存中维护两个记录器来记录位置即可,但是如果换成多对多就模型就很麻烦,要考虑的是记录器的状态正确性和多个任务同步工作。
在代码运行的临界区的时候要考虑的是状态同步性和状态的一致性,多线程环境下怎么保证数据一致性?临界区里面的资源是不能多个线程操作的,在同步原语的原则里面有下面几种规则,如下:
- 互斥访问:在同一时刻,最多只有一个线程能加入临界区操作资源。
- 有限等待:当一个线程进入临界区的时候,操作时间是有限的不能无限,必须获得许可才能进入临界区,操作完成之后应立即释放许可,让出资源给其他线程。
- 空闲让出:如果临界区是空闲的,应该从多个需要进入临界区的线程中选择一个进入临界区并且执行,保证程序能正常运行。
单核处理器
不要觉得单核处理器在处理任务时同步是很简单,恰恰相反也互存在多个任务同步情况。为了支持多个程序并发运行,现在操作系统都引入了分时调度的算法,也就是时间片分时执行任务,这个问题是由于调度器不同的切换上下文交叉执行任务导致的,也会出现数据竞争问题,本节将看看单核处理器下的任务同步处理。
package main
import (
"fmt"
"sync"
)
var (
sendIndex, revIndex = 0, 0
buffer = [3]int{}
wg = new(sync.WaitGroup)
)
func main() {
producer(6)
producer(8)
producer(9)
fmt.Println(buffer)
fmt.Println(consumer())
fmt.Println(consumer())
fmt.Println(consumer())
producer(99)
fmt.Println(buffer)
fmt.Println(consumer())
producer(88)
fmt.Println(buffer)
fmt.Println(consumer())
}
func producer(n int) {
for sendIndex == len(buffer) {
// 没有位置就一直循环阻塞
if revIndex == len(buffer) {
sendIndex = 0
break
}
}
buffer[sendIndex] = n
sendIndex++
}
func consumer() int {
for sendIndex == 0 {
// 没有元素就一直循环阻塞
}
n := buffer[revIndex]
if revIndex == len(buffer)-1 {
// 消费到最后一个了,重置
revIndex = 0
sendIndex = 0
} else {
revIndex++
}
return n
}在线运行代码地址:https://go.dev/play/p/FZHEwDhafQ_C
即使是单核也会出现数据竞争,状态同步的问题,单核CPU在操作系统的帮助下可以运行多个进程,如下图,单核多核心处理器的上下文切换,通过时间片的方式进行的:
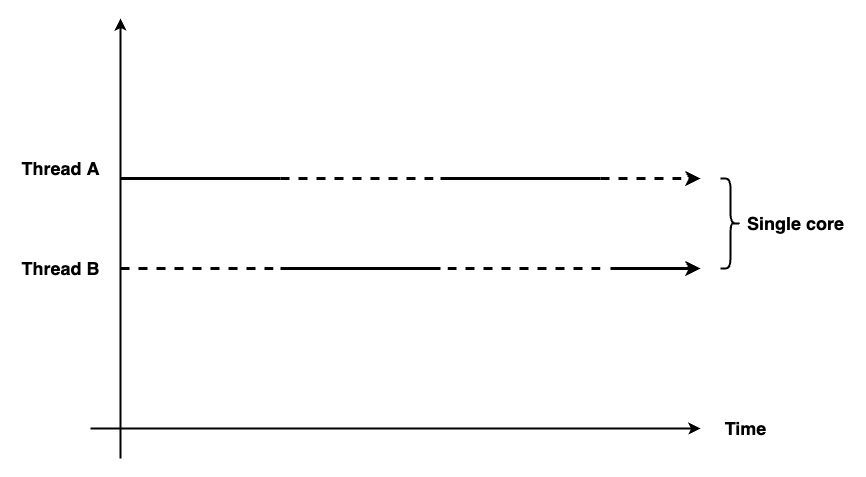
例如上面就用代码模拟一个1:1生产者和消费者模型,在并行操作中很常见,当然当前的程序是串行执行的并不是并行处理的;如果是并行处理那么记录器就出错,当多任务处理的时候要保护临界区的代码,让其他并行变成同步操作,同步原语就是要解决这个问题的设计方案。下面这是记录器临界区的代码,要帮助多个的生产者操作这款数据的时候是有先后顺序的,状态是同步的:
var (
sendIndex, revIndex = 0, 0
buffer = [3]int{}
wg = new(sync.WaitGroup)
)单核多任务进入临界区的问题,很好解决已经有硬件解决方案了,操作系统在调度一个任务从上一个切换到下一个的任务的时候,都有时钟中断造成的。所以如果在程序进入临界区的时候把中断指令发生器关闭掉,这样一个任务进入临界区的时候就不会发生上下文切换,就不会产生多个任务竞争的情况,就避免了被操作系统调度器抢占式调度了,这样就能保证临界区只要一个线程在运行,其他线程等待本线程结束之后开启中断指令,才能正常进入临界区。
看似一个很简单并且实现也不难的方案,但还是有一些问题的,例如进去临界区之后线程有Bug卡死了怎么办?是不是意味着程序一直运行中,卡在哪里?怎么解决?就会出现死锁Deadlock的问题。
多核处理器
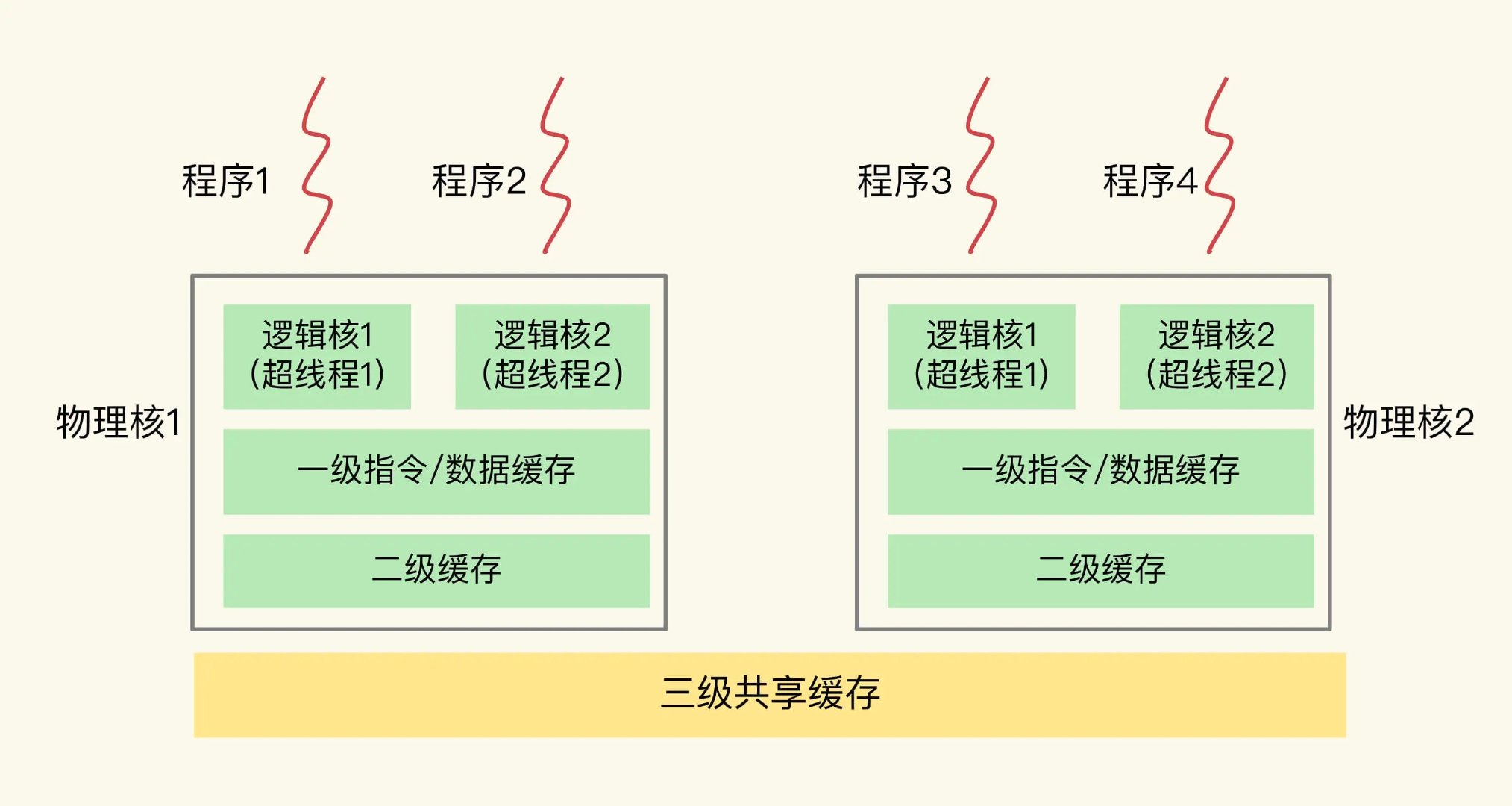
在单核处理器用硬件设备的开中断和关中断是可以达到临界区的的数据安全性;但是如果这个放到多核上就做不到了,因为多核心是并行计算着的,如果想到达临界区的安全性那么就要关闭其他核心,只有一个核心运行并且关闭硬件中断。这么做的话就会让其他核心上的任务停止下来,变成单核计算,发挥不了多核计算能力,所以这种方案是毫无意义的,那么有没有一种新的方案可以解决这些问题呢?
Peterson Algorithm
Peterson Algorithm 是一个实现互斥锁的并发程序设计算法,可以控制两个进程访问一个共享的单用户资源而不发生访问冲突,Gary L. Peterson于1981年提出此算法。
其算法核心作用就是通过软件逻辑代码的方式实现两个独立线程互斥,原理和日常去衣服专卖店的试衣间场景差不多,但是这个试衣间只有一间,如果两个人同时进去就看谁先进去,然后把试衣间的门🚪上的标签挂上有人的提示。这样其他人看到了就不会进入试衣间,直到上一个人走出了试衣间,才能正常继续。
Peterson算法原理: 算法的核心就是标记变量,也就是对应着上面的试衣间的门上的🔐锁;在Peterson算法里面核心条件是2个条件变量,Flags与Turn,其中Flags[N]的值为true那么就可以认为是下标为N的线程希望能进入该临界区,而变量Turn保存有权访问共享资源的进程的下标号则Flags[N],流程图如下:
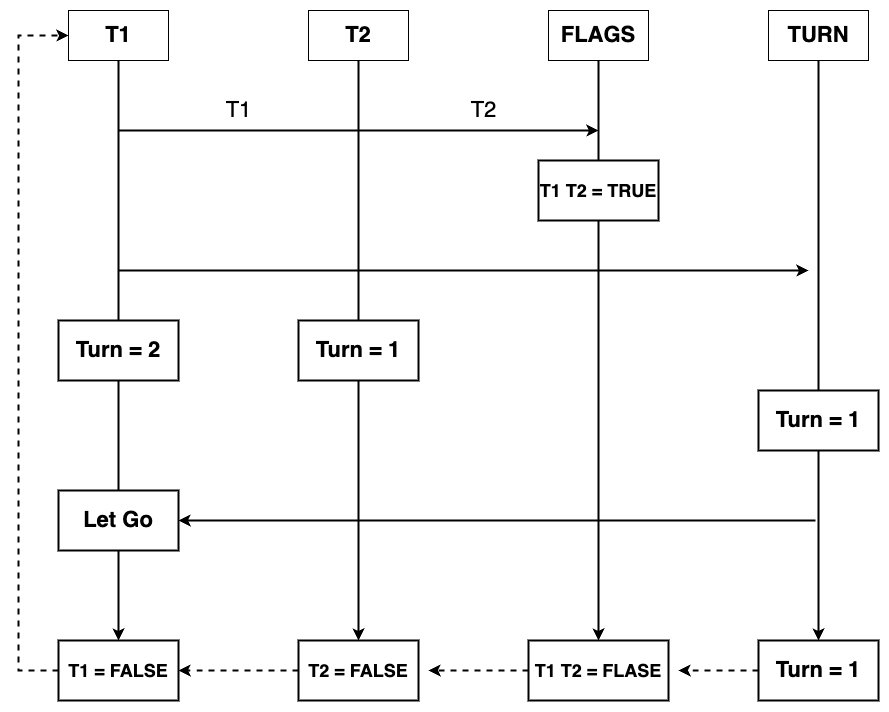
那么根据上面的理论,可以推理出来一个互斥条件公式:(Flags[0] == true && Turn == 0) != (Flags[1] == true && Turn == 1),伪代码实现如下:
// Peterson Algorithm
package main
import (
"fmt"
"time"
)
var (
flags = [...]bool{false, false}
turn = 0
area = 0
total = 100
)
func main() {
for i := 0; i < total/2; i++ {
go t1()
}
for i := 0; i < total/2; i++ {
go t2()
}
time.Sleep(2 * time.Second)
fmt.Println(area == total)
}
func t1() {
// 为了验证结果才加的这个条件
for area != total {
flags[0] = true
turn = 1
// 如果是对方就阻塞
for flags[1] == true && turn == 1 {
// 阻塞着 不进去临界区
}
// 进临界区
area += 1
// 出临界区
flags[0] = false
}
}
func t2() {
for area != total {
flags[1] = true
turn = 0
// 如果是对方就阻塞
for flags[0] == true && turn == 0 {
// 阻塞着 不进去临界区
}
// 进临界区
area += 1
// 出临界区
flags[1] = false
}
}在线运行代码地址:https://go.dev/play/p/w92UsJgVhTq
整个工作流程的话很简单,首先Flags的默认值都是false并且Turn的值为线程编号的随机下标的中其中一个,当两个线程并行工作的时候都会其对应的Flags[n]设置为true;Flags[n]值为true才能满足申请进入临界区的请求,但是还需要一个Turn,Turn才是决定哪个先进入临界区的必要条件,因为两个线程都是并行执行的所以对Turn的修改是随机2/1次。Trun只会是下标为0至1之间的数,只要Turn确定下来了就可以满足互斥的条件了,当进入临界区的线程执行完成之后会把Flags值设置为false,让其不满足互斥条件然后递归操作。
Peterson算法缺点: 看似完美的通过软件编码的手段解决了同步问题,但是简单的Peterson算法只能解决2个任务之间同步问题,如果要支持更多任务需要对其改进再使用。另外Peterson算的严格要求CPU在执行指令的时候是顺序执行不能跳转执行,否则就不能达到满足同步原语的3个条件;如果CPU乱序执行的话就不能达到Peterson算法的设计原则,从而也无法达到任务之间的互斥。
Atomic Operation
原子操作如果写过数据库开发写过SQL应该知道事务功能,开启一个事务也属于一个原子操作,原子操作的规则:一个或一些列的操作执行,要么全部成功执行,要么全部失败,没有中间状态;这是一个基本的原子操作的定义。
- 比较与置换 (Compare-And-Swap CAS)
- 拿取并累加 (Fetch-And-Add FAA)
在底层实现上都借助硬件提供的原子操作汇编指令完成的,只是具体的实现上有些实现代码的差异,在英特尔架构上如果要做原子操作可以使用带有lock前缀的指令进行操作。
CAS具体实现的逻辑: 会比较addr上值和expected的值是否相等,如果相等就会把原来的addr上的值替换成new_value,否则就不进行置换,然后返回addr原始值,一段具体的C代码:
int compare_and_swap(int* reg, int oldval, int newval)
{
ATOMIC();
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return old_reg_val;
}FAA具体实现逻辑: 会读取addr上的旧值,然后将其与new_value进行相加之后存放会旧地址上,而返回之前旧的值,具体的代码实现如下:
static inline int fetch_and_add(int* variable, int value)
{
__asm__ volatile("lock; xaddl %0, %1"
: "+r" (value), "+m" (*variable) // input + output
: // No input-only
: "memory"
);
return value;
}如上都通过对应平台的指令集进行完成的对应的操作的,通过x86平台提供的lock汇编指令完成的原子操作,所以这些原子操作都是依靠着硬件平台提供的功能辅助实现的,由于硬件提供了支持CPU再执行临界区的数据的时候不会被其他CPU的指令打扰保证了数据的同步安全性。
Mutex Lock

互斥锁在大部分的编程语言上都有对应的实现,都是利用硬件提供的功能做的锁实现抽象;多个线程可以共享一把锁,同时去访问一个公共的资源,每个线程并行访问资源时看谁先上锁成功,成功的就会进入临界区,离开临界区就解开锁,其他线程就可以继续抢锁执行任务,这和上面说的商场试衣间例子很接近。其互斥锁和之前讲的Linux的System V中信号量通信同步很接近,都是在有限资源下如让多个并发执行的实体能选择出一个能进入临界区访问资源的算法实现。
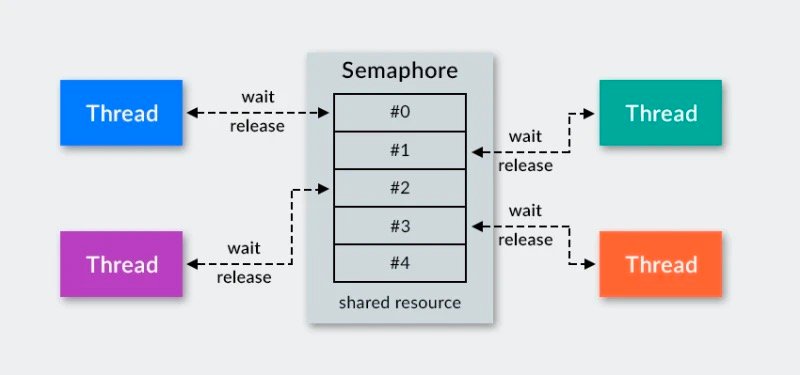
下面为我通过CAS方式实现的自旋锁:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var (
wg = new(sync.WaitGroup)
mux = new(MLock)
num = 0
total = 1000 * 2
)
func main() {
wg.Add(total)
for i := 0; i < total/2; i++ {
go func() {
defer wg.Done()
mux.Lock()
num += 1
mux.UnLock()
}()
}
for i := 0; i < total/2; i++ {
go func() {
defer wg.Done()
mux.Lock()
num += 1
mux.UnLock()
}()
}
wg.Wait()
fmt.Println(num == total)
}
// 自己实现的自旋锁
type MLock struct {
state uint32
}
func (m *MLock) Lock() {
for !atomic.CompareAndSwapUint32(&m.state, 0, 1) {
// 说明已经被占用,如果没有就设置为1
}
}
func (m *MLock) UnLock() {
// 解锁锁 CAS
atomic.StoreUint32(&m.state, 0)
}在线运行代码地址:https://go.dev/play/p/HGd8faUabhW
互斥锁实现方式很多种,这里我总结具体经典的实现自旋锁和排号自旋锁;自旋锁的实现和上面的Peterson算法很接近,全局会有一个lock变量作为标记符号,如果lock等于1说明临界区已经锁上,如果是0说明可以进行抢占,然后进入临界区。在修改变量的时候使用的是CAS算法保证一次原子操作;特点就是顺序执行看具体谁最先完成CAS原子操作就可以进入临界区,其他线程继续自旋等待状态更新。其缺点这里就看具体的线程运行速度了,如果在异构核心架构下这种情况是不能被正常采用的,因为大小核心的计算速度有差距,从而更偏向于算力更强的CPU上。
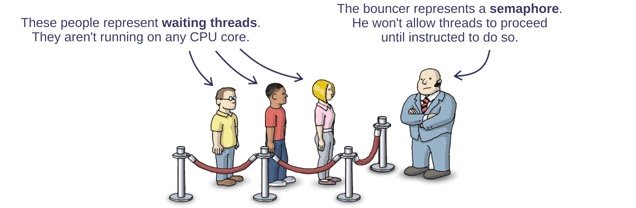
排号自旋锁(Spinlock)从名称就能看出来排号两个字,其具体实现和排号就有关系,前面讲的自旋锁是看谁随机性抢占的,没有公平性可言。SpinLock设计和现实中去医院或去银行排队办理业务的例子很像,多个线程会根据先后顺序来传递共享一把锁的使用权,排号锁相当于一个守卫或者维护秩序的保镖,会按照锁上的编号顺序把使用权传递给需要的人,锁的所有权顺序是FIFO,如下图:
具体实现就是依赖于Fetch Add Add算法的原子操作性来更新所有者编号,达到线程任务排号的效果,下面是我写一段测试代码如下:
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var (
num = 0
wg = new(sync.WaitGroup)
sm = new(SpinLock)
total = 100
)
func main() {
wg.Add(total)
for i := 0; i < total; i++ {
go func() {
defer wg.Done()
sm.Lock()
num += 1
sm.UnLock()
}()
}
wg.Wait()
fmt.Println(num == total)
}
type SpinLock struct {
// 当前所有者
owner int32
// 下一个所有者编号
next int32
}
func (s *SpinLock) Lock() {
// 第一次这里返回的是0和owner一样所以能继续
ticket := atomic_faa(&s.next, 1)
for ticket != s.owner {
// 没有在自己身上就不继续执行
}
}
func (s *SpinLock) UnLock() {
// 传递编号到下一个
atomic_faa(&s.owner, 1)
}
func atomic_faa(addr *int32, n int32) int32 {
old := *addr
atomic.AddInt32(addr, 1)
return old
}因为依靠所有者编号传递才能正常工作,所有这来的线程没有拿到锁的使用权的线程就会被阻塞,从而使大量任务变成串行的,速度非常慢,我测试了一些Benchmarking没有自旋锁快。
这两种锁是通过互斥来达到临界区资源保护作用,就和红绿灯🚥一样,都是依赖硬件设备提供的原子命令来控制信号。但是目前的实现会导致大量的任务占据CPU自旋状态,这是不行的,严重的浪费资源的;这两种锁一个在设计的时候当没有获取锁时应是阻塞状态或休眠状态,而不是一直占用着CPU。

在线运行代码地址:https://go.dev/play/p/l2zeHUJgFUo
这就和有自动启停功能的汽车一样,在等待红绿灯信号过程中,有自动启停的汽车可以自动将发动机进入休眠状态,从而来节省汽油的浪费;而目前互斥锁实现确实一个普通的版本,我们要一直踩着刹车,或者挂着空挡,而发动机会一直空转的。
小结
本篇以示例和现实生活中例子讲解了多核CPU在并行运算的时候对共享资源的竞争访问控制问题,从最基础的Peterson互斥算法到CAS和FAA算法演进实现的互斥锁解决方案,从目前的所讲解的方案来看都有缺点,并且原子操作都是依赖于真实的硬件设备提供的汇编指令才能完成,下一篇讲解如何优化自旋CPU问题。
其他资料
- Java 并发实践
- 内核同步机制
- Synchronization primitives
- Usenix Synchronization Primitives
- It's not an idea until you write it down
- UCLA Synchronization Primitives
- Deadlock
- Data Race的问题
- Deadlock Detection in Distributed Object Systems
- 威斯康辛大学:多处理器调度
- Peterson Algorithm Wiki
- Peterson算法
- Synchronized 同步锁实现原理
- Atomic vs. Non-Atomic Operations
- Go Story of TryLock Function
- Semaphores are Surprisingly Versatile
- µOS++ IIIe Semaphores
- Mutex Lock In Java
- Mutex Learning Notes In Golang
- Compare And Swap

